The hierarchy of phonemes in English language. This is the most commonly used hierarchy for phoneme classification. 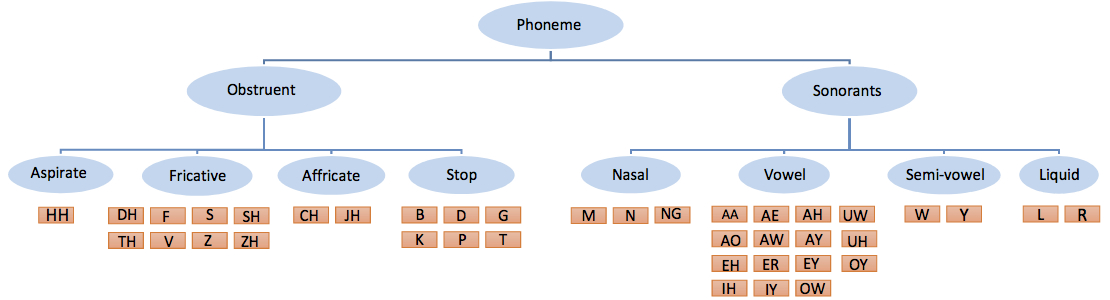 |
The numbers of all the phonemes in our dataset in blue. The mean and standard deviation of the lengths of the signals after resampling in red. 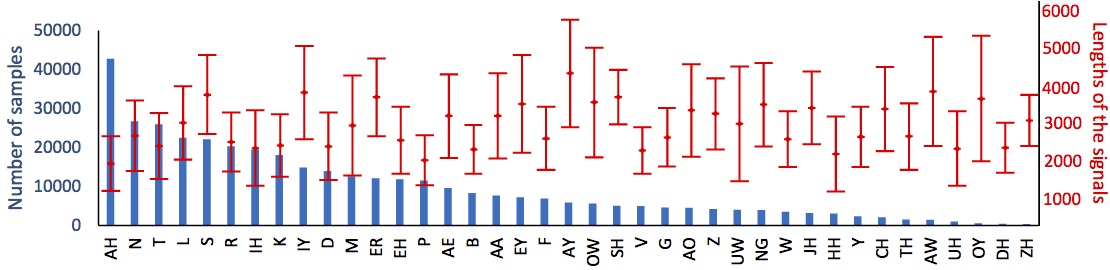 |
Two examples. Each tree shows the unknown phoneme, its waveform and the source word at the root. The three leaf nodes of a tree show the three classes the algorithms produce. waveform and the source word are shown. 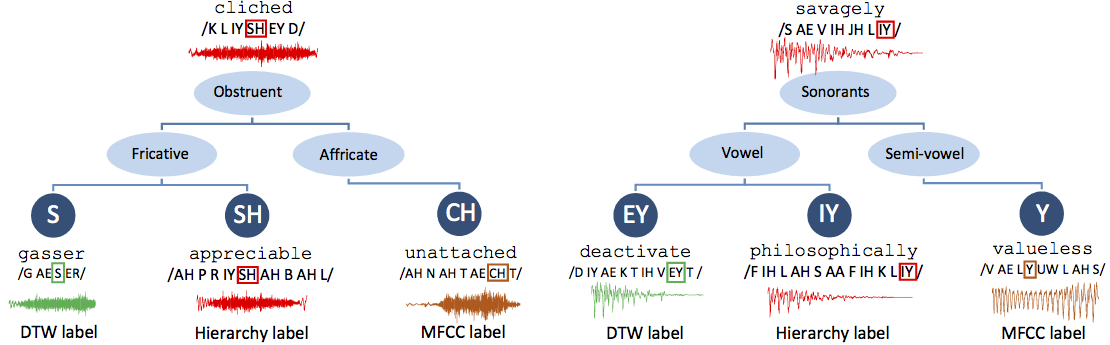 |
(left) Envelopes U and L for the candidate (blue) sinusoid over different windows. (right) LB Keogh using the prefix of the longer signal. (top) The query shown in black is the shorter of the signals of length 2300. Note that, the difference in length between the blue and the black signals is equal to the window size 8% of the longer signal. (middle) the query in black is of length 2000 where window size is 20% of the longer. (bottom) the query in black is longer than the blue candidate and only its first 2500 samples are used for the bound. 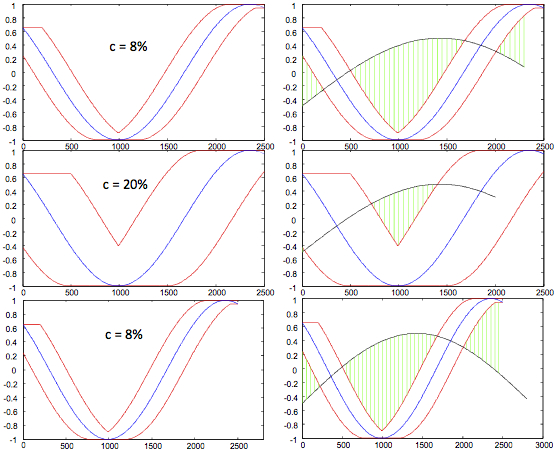 |
Incremental accuracy of the algorithms in the top two layers of the hierarchy on three test sets. (left) Google, (middle) Oxford and (right) Merriam-Webster. 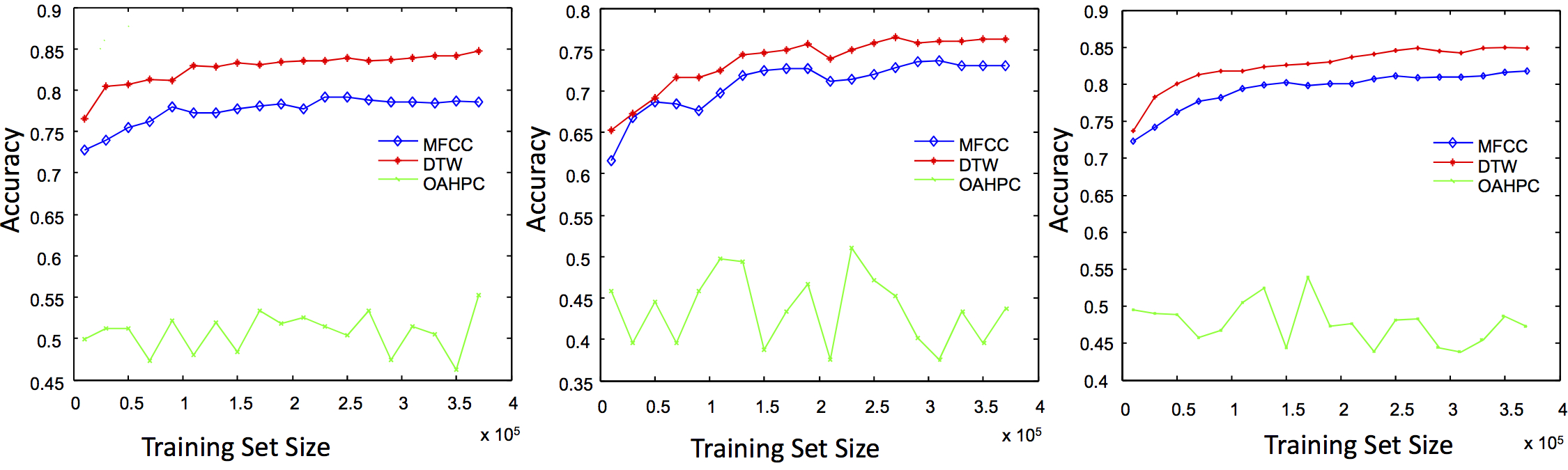 |
Incremental accuracy of the algorithms in whole of the hierarchy on three test sets. (left) Google, (middle) Oxford and (right) Merriam-Webster 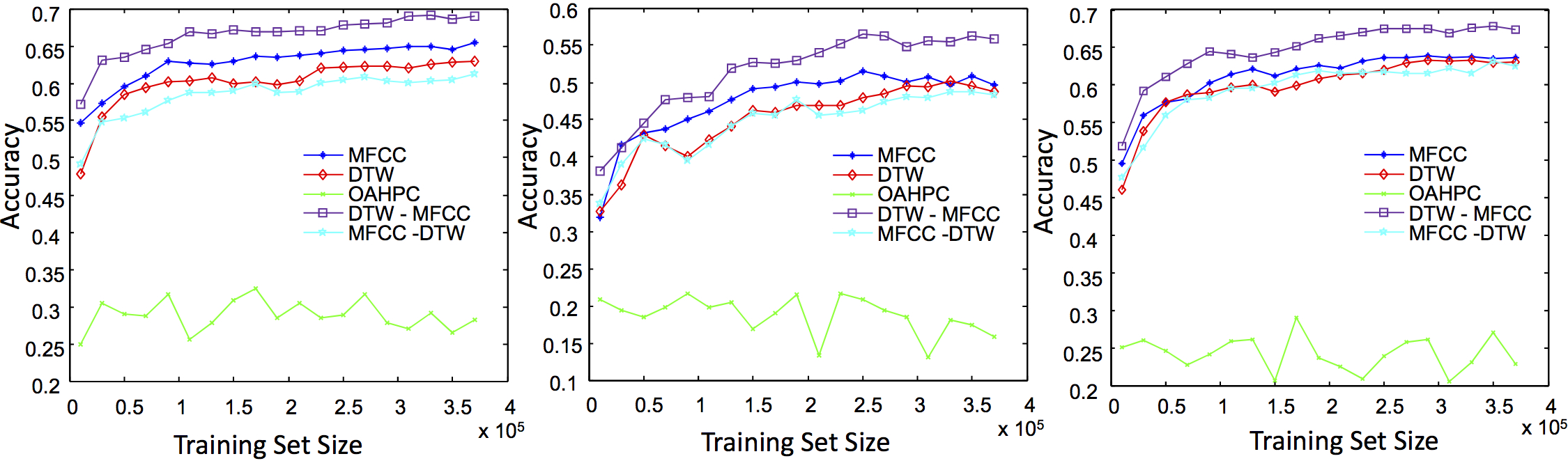 |