Basic Graduate Evolution
Table of Contents
Notes
Review genetic basics
DNA and RNA
nucleotide ≅ base
Bases
- purines (A T), 3 H bonds, less stable (fewer bonds)
- pyrimidine (GC), 3 H bonds
| RNA | normally single stranded |
| DNA | double stranded |
Each strand has a 5' end and a 3' end. The convention is to write from the 5' and to the 3' end when transcribing DNA. The strands are anti-parallel.
RNA (as compared to DNA)
- single stranded
- much shorter (often 20-24 nucleotides long)
- Bases: (A C G U)
Genes
- traditionally, something that codes for a protein, i.e., gene → messenger-RNA → protein (this was previously the only functionality known for DNA segments)
- now, genes also include sequences which do other things, e.g., transcribe RNA, some RNA sequences are functional as themselves
Types of Genes
- protein coding
- RNA
- regularity
Eukaryotic protein coding genes comprise both transcribed () and non-transcribed () parts.
Gene's are transcribed by polymerase, which first anchors to a "promoter region" which flanks the gene, and then travels the gene transcribing its contents.
A "codon" is 3 nucleatides which are transcribed into 1 amino-acid.
Gene Structure (we're talking about protein coding gene)
- TATA box
- in the promoter region -19 from the gene start, in a GC-rich region of the DNA. Not required, but prevalent
A Gene with the promoter region.
promoter region Gene->
----> -- <--- -- ---------- -------- ---------
GC CAAT GC TATA
box box box box
RNA polymerase
| I | RNA |
| II | protein coding |
| III | small RNA |
- Genes specifying proteins
Transcription and Translation process
- DNA -> pre-RNA (which does include non-coding introns)
- pre-RNA -> mature mRNA, this is done by the spicing machinery (these arose early in evolution and are very intricate machines). Genes are spliced using the "GT-AT rule" (introns often start with GT and end with AG)
- Mature mRNA -> the remainder of the gene is split up into codons and transcribed, it must start with one of three start codons (UGA UAA UAG). The start code does not code for an amino acid. This is still capped by small untranslated sections on either side.
- Protein -> only the translated regions converted to amino acids
There are many other regulatory sequences in introns or between genes which do things like increase or decrease the speed of translation.
- RNA-specifying genes (transcribed to RNA, not translated to protein)
- transfer RNA
- ribosomal RNA
- similar sequences between (eukaryotes and prokaryotes) which means they arose early and are important
Degenerate genetic code
- 20 Amino Acids
- 64 codons (4 × 4 × 4)
- Regulatory Genes
- regulate the expression of another gene
- not transcribed or translated
enhancers or repressors (change tempo of translation)
notable examples
- replicator genes
- initialize and terminate replication
- telomeres
- "cap" at the end of a chromosomes, these erode with age, these don't erode as quickly in sea turtles
- segregator genes
- help split the DNA pair (sisters) for translation, this is where the zippers attach to unzip
- recombination genes
- sites for recombination during meiosis (crossover more likely to happen here)
Amino Acids
Composed of
- a central carbon
- an amino end
- a carboxyl end
- a hydrogen
- a side chain – this is the most variable and the most important
Simplest is glycine
- single H side chain
- fits in nooks and crannies of proteins
Five classes
- positively charged
- negatively charged
- hydrophobic
- neutral
- special
Protein
string of amino acid
- secondary structure – two most common 2-D structures for folded proteins
- α helix
- β pleated sheet
- tertiary structure – these combine into 3-D structures of the protein
- quartinary structure – two tertiary molecules
More genetic basics
phase
Losing the phase (correct codon alignment) can be caused by mutations and garbles the translation resulting in a garbled protein. The phase is determined by the start or initiation codon, and is called the "reading frame" or "open reading frame" (ORF).
degeneracy
Genetic code is degenerate but not ambiguous.
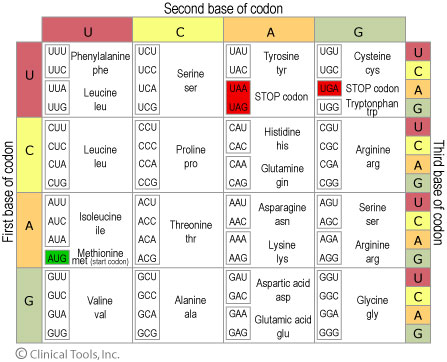
Multiple codons coding for an amino acid will often differ in the third position.
Terminology
- fourfold-degenerate site
- any nucleotide in this position will specify the same amino acid.
- twofold-degenerate site
- two of the four nucleotides at this position will specify the same amino acid.
- non-degenerate site
- every nucleotide here results in a different amino acid, called an "amino-acid substitution".
- synonymous codons
- different codons which code for the same amino acid.
In most codons the first two positions are non-degenerate sites.
numbers of codons
- 61 sense codons (remaining 3 are STOP codons)
- 549 possible codon nucleotide substitutions
- 61 codons × 3 positions × (4-1) alternatives for each position
- assuming equally probable mutations (not true), then 70% of all 3^{rd} position changes are synonymous
- 2^{nd} site is the most sensitive to substitution, 0% of changes are synonymous
- in the 1^{st} site only 4% of changes are synonymous
Main evolutionary forces (on populations)
- mutation
- selection
- migration (new alleles from outside)
- drift
mutations
Mutations are hereditary changes in the genetic material due to errors in DNA replication or DNA repair.
Types of mutations
- substitutions
- recombination (crossing-over and gene conversion)
- deletions/insertions ("indels")
- duplication
- inversions
Evolutionarily mutations that occur in germ cells are the only hereditary ones.
- classes of mutations
- substitutions
also called "point mutations"classifications
- transitions (purine to purine, pyrimidine to pyrimidine), there
are four possibilities for this
- a ↔ g
- t ↔ c
- transversions change the type, there are eight possibilities for this
If these were equally likely you would expect twice as many transversions as compared to transitions.
You actually see many more transitions than translations.
Also classified by effect (only applies to protein coding genes)
- silent or synonymous (no amino acid change)
- replacement or non-synonymous (cause aa change)
- missense (now codes a new aa)
- nonsense (changes to a termination codon, will prematurely terminate translation)
- transitions (purine to purine, pyrimidine to pyrimidine), there
are four possibilities for this
- crossing-over and gene conversion
- homologous recombination
- occurs between strands which are similar through a shared common ancestry
This happens most often during repair. Say a chromosome breaks (very common) there is a machine which comes along and repairs the broken chromosome (sometimes this causes a change).
This also happens during meiosis.
Two types of homologous recombination
- crossing over (reciprocal recombination), two chromosomes pair up and each gets a bit of the other
- gene-conversion (nonreciprocal recombination), a bit of one goes to another, but one remains unchanged
- insertions and deletions
- unequal crossing over
- May be caused by unequal crossing over,
this is often caused by similar sub-sequences, this could cause
an insertion and a deletion. Generally 10-13 nucleotides long.
-----=====----- ------------- x ---------======----- -----====---====------ - replication slippage
- (look up in a text book), when a repeating pattern is offset. These can be thousands of base pairs long
- retro-transposition
- Selfish elements which are prone to copy themselves anywhere throughout the genome (discovered by Barbara McKlintoc in corn). Sometimes these elements will grab a nearby section of the sequence and bring them along.
- inversion
A rotation of a double-stranded segment by 180.| | a b c d e f g h to a d c b e f g h
These often occur between genes where they don't have much effect.
- substitutions
- spatial distribution of mutation
Often 100-fold differences in mutation rates between elements of the sequence. These are often very repetitive sequences of the genome.Some groups of nucleotides are prone to change. E.g.,
CGis easily methelated causing the C to become a T.TTis also a hot spot.palindromes
epigenetics (non-genetic), e.g., chemical elements changing genetic interpretations.
- chemicals inhibiting expression
- proteins binding up DNA into little balls, by histomes, this inhibits transcription
- substitution in non-coding sequences and pseudo-genes
important to determine the pattern of spontaneous mutationno selective pressure
mutation accumulation experiments, you maintain the lowest possible population size
you could bottleneck a population, no selection, only genetic drift
Pseudo-genes are dead (premature STOP or something), these can also indicate baseline rates.
- can compare to an active duplicate
- can compare to a homolog (inactive in people, compared to active in chimps)
Trend from GC to AT, so non-coding regions become
AT-rich.
Dynamics of Genes in Populations
- Q
- Why does population size matter?
- A
- Selection does not work in small populations.
Evolution as a population-level process
Big "macro-level" changes (e.g., between species) are results of the same small "micro-level" changes between individuals.
Four major evolutionary forces
- mutation
- random genetic drift – ∃! animal, the Atlantic eel, which has an effectively infinite population size, because they all come together to one place annually to mate.
- natural selection
- gene flow
The study of gene changes in populations is population genetics.
- what influences mutant allele over time
- how is genetic variability maintained
- probability of going to fixation
- how fast will replacement take place
- influence of chance effects on molecular genetic change
Definitions
- locus
- chomosomal location of a gene (often a synonym for gene)
- allele
- alternate forms of a gene
- allele frequencies
- relative proportions of alleles in a population
- genotype
- genetic constitution of an individual
- phenotype
- observable characteristic or trait of an organism
- discrete trait
- finite number of phenotypes in discrete classes, often controlled by one or a few genes
- continuous or quantitative trait
- what is sounds like, controlled by at least 100 genes, most traits fall into these categories
- homozygous vs. heterozygous
- whether alleles are of the same type or different
- genotypic vs. phenotypic ratios
- dominant vs. recessive allele
- expressed
- evolution
- change in allele frequency
- natural selection
- differential reproduction of genetically distinct individuals or genotypes within a population
- fitness (w)
- measure of an individuals ability to reproduce
- absolute fitness – total progeny (might only count progeny which make it to reproductive age)
- relative fitness – progeny relative to rest of the population, the most fit genotype is assigned a fitness of 1
Punnett Square
- BB is homozygous
- Bb is heterozygous
Mendel bred purple × purple plants and got both purple and white plants. Specifically 705 purple and 224 white.
Diploid parent will produce single-ploid gametes (else there would be a combinatorial explosion in the ploidy of the offspring).
A Punnett Square
| pollen | |||
|---|---|---|---|
| B | b | ||
| pistil | B | BB (purple) | Bb (purple) |
| b | Bb (purple) | bb (purple) |
- phenotypic ratio of above is
- 3 purple
- 1 white
- genotypic ratio of above is
- 1 BB
- 2 Bb
- 1 bb
Changes in allele frequencies
Problem
- 1000 peppered moths in Manchester
- dark melanic form of allele is dominant (M)
- ancestral is recessive (m)
- 825 melanic
- 175 peppered
- 512 of melanic are heterozygous
Some calculations
- Phenotypic ratio is 875/175 or 4.7 melanic to peppered
- Genotypic ratio is 313 MM, 512 Mm, 175 mm or 1.78 : 2.93 : 1
- Allele frequencies of M and m 616 + 512 / 2000 = 0.569 (2 * 175) + 512 / 2000 = 0.431
Allele frequencies are changed by
- selection
- drift
- migration
2 Mathematical approaches
- deterministic
- (analytic) can predict changes unambiguously. The first of these was "Harvey Weinberg".
- stochastic
- probabilistic, associates probability distributions with environmental conditions
Deterministic assumptions
- infinite population size
- constant environment
Needed for Darwinian selection (influenced by Menthusian principles)
- variation
- environmental limit to population size (carry capacity)
- differential reproduction (because of the above)
Types of mutation
+------------ mutation ------------------+
| | |
| | |
| | |
deleterious neutral advantageous
| | |
| | |
| | |
| | |
purifying chance positive selection
selection events or
overdominant
selection
Normally selection reduces genetic variation, however "overdominant" selection can increase genetic variation. This is when the heterozygote has the highest fitness.
Hardy-Weinberg principle
1 locus, 2 alleles (A_{1} A_{2})
- 3 possibly diploid genotypes
- allelic frequencies are
- f(A_{1}) = p
- f(A_{2}) = q
- p + q = 1
| genotype | A_{1}A_{1} | A_{1}A_{2} | A_{2}A_{2} |
|---|---|---|---|
| p^{2} | 2pq | q^{2} |
genotypic frequencies
- f(A_{1}) = p^{2}
- f(A_{2}) = 2pq
- p + q = q^{2}
This is the null model.
Back to our problem.
- melanic is dominant and is 87% (could be heterozygotes)
- → 13% is non-melanic
- → q = 0.13
- → q = \sqrt{0.13} = 0.36
- → p = 1 - q = 0.64
- → f(Mm) = 2pq = 2 × 0.36 × 0.64
Graph (frequency of a, by frequency of genotype in population)
set xrange [0:1] set xlabel 'frequency of A' plot x * x title 'AA', (1-x) * (1-x) title 'aa', 2 * x * (1-x) title 'Aa'
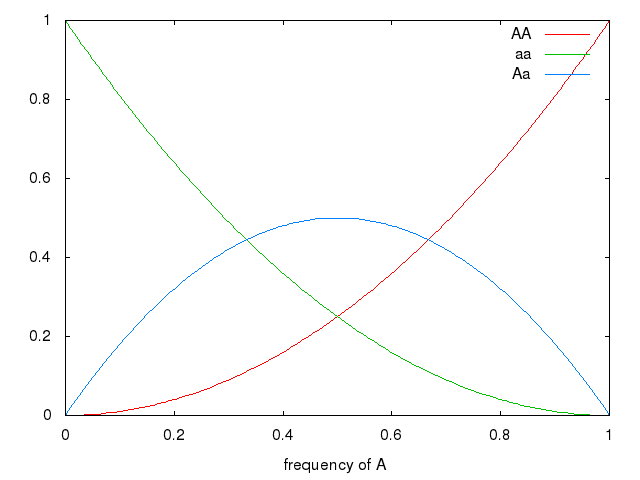
Natural Selection changes allelic frequencies
| genotype | A1 A1 | A1 A2 | A2 A2 |
|---|---|---|---|
| fitness | w11 | w12 | w22 |
| frequency | |||
| after | p * p w11 | 2pqw12 | q * q * w22 |
| selection |
change in frequency \begin{equation*} \delta q = q' - q \end{equation*} \begin{equation*} \delta q = \frac{pq(p(w_{12} - w_{11}) + q(w_{22} - w_{12}))}{p^{2}w_{11} + 2pqw_{12} + q^{2}w_{22}} \end{equation*} Example
- heterozygous individuals have lighter eye spots (increased predation)
- relative fitness of genotypes
SS 1 Ss 0.9 ss 0.6 - p(S) = 0.7
p = 0.7 q = 0.3
Frequencies in the original
| p | 0.49 |
| pq | 0.09 |
| q | 0.42 |
Relative fitness
| p | 1 |
| pq | 0.9 |
| q | 0.6 |
Next generation frequencies
- f(SS)' = p^{2}w_{11} = 0.49 × 1
- f(Ss)' = 2pqw_{12} = 0.42 × 0.9
- f(ss)' = q^{2}w_{22} = 0.09 × 0.6
Next generation's allelic frequencies
- f(SS) × 2 + f(Ss)
- f(ss) × 2 + f(Ss)
Terms
- epigenetic
- Heritable changes in gene expression caused by mechanisms other than changes in the underlying DNA sequence.