Dissertation Proposal: Evolving Robust Software
Table of Contents
1 Introduction
Over the past fifty years software developers have been selecting, reusing and modifying efficient and robust software development tools, code and design patterns. This history of development, through a process mirroring natural selection, results in some surprisingly biological features of software which this proposed work will investigate and exploit.
The dual goals of this investigation are increased understanding of existing software, and new tools for software development and maintenance. I will focus on properties that are exhibited by evolved complex systems and arise through natural selection and adaptation to survival in the world. Some properties, such as the amenability to random evolutionary processes and robustness to variability in constituent parts, will be shown to be applicable to engineered software systems.
My hypothesis is that similar properties lead to the persistence and replication of both living and engineered systems. These properties include robust functioning in an environment and the ability to adapt (or be adapted) to new environments. Specifically, like their biological counterparts, software artifacts which have stood the test of time including applications, interfaces, operating systems, programming languages, compilers and linkers all display robustness and adaptability.
I discuss recent methods of software development and maintenance that make use of software robustness, and I propose new tools and techniques which leverage this natural robustness of software. By extending our understanding of the similarities between engineered software systems and evolved biological systems, software may be engineered to be more robust and evolvable, benefiting software developers and consumers.
Motivation: Over the previous half century the production and maintenance of software has emerged as an important industry, consuming the efforts of 1.3 million software developers in the US alone in 2008, a number projected to increase by 21% by 2018 bureau2011computer. Investigating the evolved properties of software systems will challenge commonly held folk wisdom of software fragility, leading to new tools and techniques such as those discussed in the preliminary and proposed work below. My research goals are to produce increasingly robust software and to reduce the cost of software maintenance.
Investigating software robustness could shed light on fundamental properties of the robustness of evolved systems. The field of digital evolution encompasses the design and analysis of computational models of biological evolution, permitting evolutionary time frames, controls, and metrics that are not feasible in-situ. Real world engineered software offers not just a model, but an instance of a robust evolved system schulte2012smutationalrobustness. Real world software is more complex than artificial models, has non-contrived fitness functions, and a development shaped through real world competition.
Opportunity: Recent developments in software engineering and evolutionary biology make this an opportune time to pursue this topic. The two fields increasingly overlap, with biologically inspired computational techniques being applied to the maintenance of software systems weimer2009automatically, and software performance being discussed in biological terms bealengineered.
The software engineering community is moving from ideas of provable correctness towards notions of sufficient correctness and adaptability rinard2009survival, radul2009art, perkins2009automatically, rinard2004enhancing, and my proposed research is well poised to take advantage of and promote this shift in priorities.
Overview: In the remainder of this proposal I first review related work (Section related-work). The research plan is divided into two chapters, focusing on an investigation of software mutational robustness (Section mutational) and development of applications that leverage software robustness (Section applications). A workplan and timeline for completion of the proposed research is presented (Section timeline), and the proposal concludes with a discussion of the expected impact of this research and possible future extensions (Section conclusion).
3 Mutational Robustness
In preliminary work, we show software to be mutationally robust schulte2012smutationalrobustness. We define the mutational robustness of software as the percentage of software mutants that are functionally equivalent to the original program. We demonstrated software to be robust to mutation of its source and assembly code. This insight has multiple implications for both the nature of software and potential new software tools. In the remainder of this section I further explain the concept of software mutational robustness and share preliminary results in Section soft-mut-rb, and propose ways to extend this insight to increase our understanding of software in Sections comparative-robustness and correlates-of-mut-rb.
3.1 Software Mutational Robustness
Let "syntax space" be a space of the text of program source code, and let "semantic space" be a space of the functionality of program behavior. Compilation (with a set compiler and flags) will then be a function from syntax space to semantic space. Given a program we apply syntactic mutations and observe the semantics of the resulting mutations.
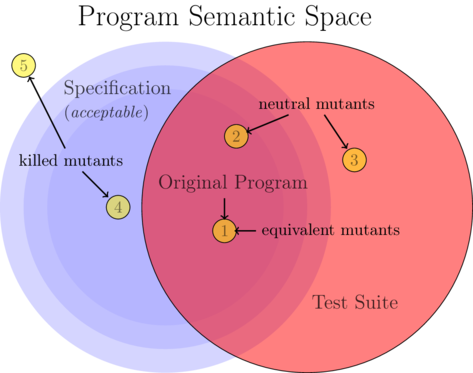
Figure semantic-space shows the semantic space surrounding a program. The lavender "Specification" region contains those programs with acceptable semantics, whether defined through a formal specification or loosely by the developers or users of the program. The red region holds those programs with acceptable behavior as defined by the test suite. Ideally the original program lies within the intersection of these two regions, and their exclusive disjunction is small
The mutation testing community uses mutation operators specifically designed to produce faulty program mutants. Mutation testing assumes that all mutants are either faulty or equivalent, i.e., the lavender Specification region in Figure semantic-space does not extend beyond the point of the original program. A "mutation adequacy score" jia2010analysis accesses the quality of the test suite as the percentage of non-equivalent mutants which fail some test. Through seeking to optimize this score mutation testing drives the Test Suite region to similarly approach the single point of the original program in semantic space.
By not allowing for the possibility of non-faulty non-equivalent mutants (i.e., by not acknowledging mutants 2 or 4 in Figure semantic-space), the mutation testing approach ignores the functional (or neutral) variants which much of this work will seek to exploit1.
We define software mutational robustness as the percentage of random mutations to a given software instance that leave the observable functionality unchanged. We assume that mutants which satisfy the test suite will also satisfy the specification, and thus determine mutant fitness using the software's existing test suite. Only those variants that successfully compile and pass all tests in the test suite are considered neutral. Mutation operations are restricted to those portions of the program exercised by the test suite to ensure that all mutations will have some affect on software runtime behavior as exercised by the test suite.
Insert AST 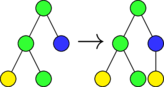 |
Delete AST 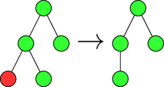 |
Swap AST 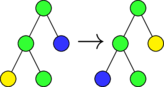 |
Insert ASM 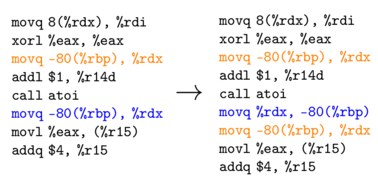 |
Delete ASM 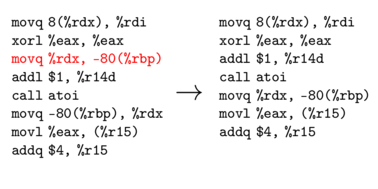 |
Swap ASM 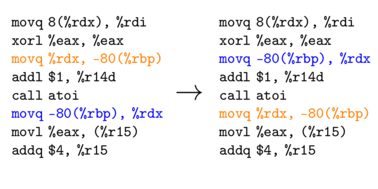 |
In preliminary work we tested mutational robustness at two levels of software representation; abstract syntax trees parsed from source code and linear sequences of compiled assembly code instructions. The three mutation operations are shown applied to both of these representations in Figure mut-ops.
3.1.1 Experimental Results
We tested the mutational robustness of 22 programs including production software projects, the Siemens benchmark suite hutchins1994experiments, and a small number of hand-crafted exhaustively tested programs. Each of the three classes of programs serves a different purpose. The sorting algorithms have complete test suite coverage ensuring that each statement, branch, and assembly instruction is evaluated by the test suite. The Siemens programs provide for comparison of our work to the large amount of previous work in mutation testing. The Siemens programs also demonstrate that our results apply to extremely well tested software in which each branch and def-use pair is covered by at least 30 test cases. The third class of programs demonstrates that mutational robustness is a property of real world software programs used in everyday systems. The results of these experiments are shown in Table mut-rb-results.
| Program | ASM LOC | C LOC | # Test | % Cov. | AST Rbst. | ASM Rbst. | Description |
|---|---|---|---|---|---|---|---|
| Sorting algorithms | |||||||
| bubble-sort | 184 | 34 | 10 | 100 | 27.3 | 25.7 | integer sorting |
| insertion-sort | 170 | 29 | 10 | 100 | 29.4 | 26.0 | integer sorting |
| merge-sort | 233 | 38 | 10 | 100 | 29.8 | 21.2 | integer sorting |
| quick-sort | 219 | 38 | 10 | 100 | 28.9 | 25.5 | integer sorting |
| Siemens Benchmarks | |||||||
| grep | 28776 | 10929 | 119 | 24.9 | 50.0 | 36.7 | text search |
| printtokens | 2419 | 536 | 4130 | 81.7 | 21.2 | 25.8 | lexical analyzers |
| schedule | 922 | 412 | 2650 | 94.4 | 34.4 | 29.1 | priority schedulers |
| sed | 17026 | 8059 | 360 | 42.0 | 33.0 | 25.6 | text manipulation |
| space | 18098 | 9126 | 13494 | 91.1 | 37.7 | 32.1 | array def. lang. int. |
| tcas | 544 | 173 | 1608 | 96.2 | 33.5 | 25.9 | collision avoidance |
| Real World Programs | |||||||
| bzip2 1.0.2 | 18756 | 7000 | 6 | 35.9 | 33.0 | 26.1 | compression |
| — (alt. test suite) | 22 | 71.0 | 46.4 | 23.6 | |||
| ccrypt 1.2 | 15261 | 4249 | 6 | 29.5 | 33.0 | 69.7 | encryption |
| — (alt. test suite) | 16 | 40.4 | 34.6 | 69.7 | |||
| imagemagick 6.5.2 | 6128 | 147 | 145 | 0.8 | 33.3 | 66.3 | image manipulation |
| jansson 1.3 | 6830 | 2975 | 30 | 28.8 | 33.3 | 28.0 | data serialization |
| leukocyte | 40226 | 7970 | 5 | 45.4 | 33.3 | 39.9 | computational biology |
| lighttpd 1.4.15 | 34165 | 3829 | 11 | 40.1 | 61.5 | 56.9 | webserver |
| nullhttpd 0.5.0 | 5951 | 5575 | 6 | 64.5 | 41.5 | 37.8 | webserver |
| oggenc 1.0.1 | 299959 | 59094 | 10 | 38.4 | 33.4 | 22.1 | audio codec |
| — (alt. test suite) | 40 | 58.8 | 40.5 | 72.3 | |||
| potion 40b5f03 | 80406 | 15033 | 204 | 48.4 | 33.3 | 48.9 | language interpreter |
| redis 1.3.4 | 44802 | 17203 | 234 | 9.2 | 33.3 | 34.0 | key-value data |
| tiff 3.8.2 | 22458 | 1732 | 10 | 15.4 | 33.3 | 90.4 | image manipulation |
| vyquon 335426d | 20567 | 4390 | 5 | 50.6 | 33.3 | 69.0 | language |
| total or average | 664100 | 158571 | 23151 | 40.9 | 33.9 \(\pm\) 10.4 | 39.6 \(\pm\) 21.5 |
For each program, at both the AST and ASM level, we generated at least 200 unique program variants using each of the three mutation operations (insert, delete and swap). To generate these variants, mutation operations were applied at locations chosen randomly from those visited by the test cases. On average, roughly 37% of randomly generated program variants in this sample were neutral.
One possible weakness of these results is the use of a program's existing test suite to determine the functionality of program variants. It is often the case that existing program test suites are not sufficient to detect flawed mutants — this intuition underlies the entire field of mutation testing. To address this potential weakness we included programs with very good test suites (the sorting and Siemens programs), and we study how mutational robustness correlates with test suite coverage (Figure mut-rb-by-cov). A visual inspection of this table shows no obvious correlation, and importantly, even with 100% statement coverage at least 20% of program variants remain neutral.
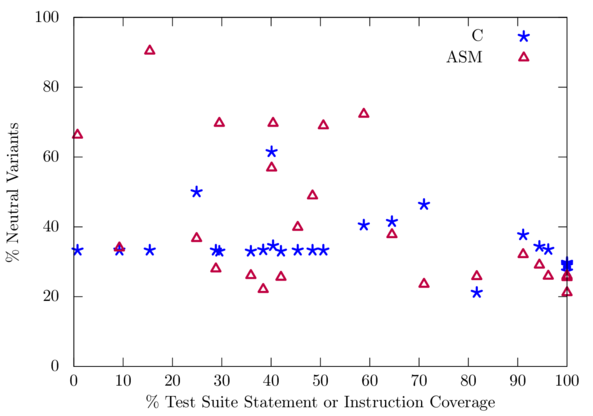
I propose to extend this work by investigating factors affecting mutational robustness (Section comparative-robustness) and those properties of software that may be related to mutational robustness (Section correlates-of-mut-rb).
3.2 Causes of Mutational Robustness
There are a number of properties of biological systems thought to cause high levels of mutational robustness. Two such factors which I will discuss below are: the mechanisms of DNA expression and the history of development through evolution.
The mapping from DNA to amino acids has evolved in such a way that similar DNA sequences give rise to similar proteins knight1999selection. Similarly, the mappings from RNA sequences to the functional shapes they produce have properties such as local continuity (promoting incremental change) and global reachability (promoting novel functionality) which are themselves thought to be amenable to evolution. schuster1994sequences, huynen1996smoothness.
If one were to design the ultimate evolvable molecule that carries information and is engaged in functional interactions, it would ideally require two features: (i) capability of drifting across sequence space without the necessity of changing shape; and (ii) proximity to any common shape everywhere. These are precisely the features that statistically characterize the mapping from RNA sequences to secondary structure. schuster1994sequences
To the degree that such properties are the consequences of the evolutionary origin of DNA and RNA, analogs should be found in other systems shaped by natural selection. The remainder of this section will investigate the hypothesis that as a product of natural selection, the mechanisms of expression of software systems should increase robustness and evolvability. I will then measure the effects of increased evolutionary development on robustness and evolvability in software developed using GP.
3.2.1 Level of Representation: Source VS. Compiled
The processes of compilation and linking of program code can be thought of as roughly analogous to the biological processes of DNA transcription and translation through which a biological genotype encoded in DNA is translated into protein structures whose interaction gives rise to a phenotype of behavior in the world. In the context of software the genotype is encoded in source code which is then compiled to generate assembly or machine code sections which are linked together giving rise to the phenotype of an executing program.
The biological processes of transcription and translation both contribute to an organism's mutational robustness. I hypothesize that the same is true of software. If this is the case, then I hypothesize both compilers and linkers contribute to software mutational robustness. In the same way that the mappings from DNA and RNA to proteins and secondary structures buffer small genetic mutations the processes of compilation and linking may buffer the effects of mutations in source code.
I propose to test this proposition by comparing the robustness of mutations to source code (before it is compiled and linked to form an executable), assembly code (before it is linked to form an executable) and ELF files (which have previously been compiled and linked). I hypothesize that mutations directly to ELF files will be the least robust and mutations to source code will be more robust.
There are a number of threats to the validity of such an experiment. Most importantly the differences in representation across these levels of representation (e.g., source code is represented using trees while compiled executable code is represented using vectors) will require different mutation operators be used at each level. Any measure of mutational robustness is as much a measure of the mutation operators used as it is of the representation being operated upon. Great care will need to be taken to ensure that the operators are made as similar as possible, and the effects of any difference in operators are understood sufficiently well to ensure that observed differences are in fact due to differences in the inherent robustness of the underlying software representation.
If there are significant differences in the robustness of software across these levels then the next step would be an investigation of the specific mechanisms of compilers and linkers that enhance robustness. As one example, C compilers allow symbolic addressing to be used in source code even though direct addressing is required in assembly code. The use of direct addressing has been shown to limit the robustness of a language to mutation ofria2002design.
3.2.1.1 Preliminary Work
In preliminary work, I implemented representations allowing evolution of compiled software assembly code (ASM), and compiled and linked ELF executables. Both representations encode genomes as linear arrays of whole assembly instructions. The mutation operators used over these representations are identical to each other but differ from those used to manipulate source code level abstract syntax trees (Figure mut-ops).
3.2.2 By Provenance: Evolved VS. Engineered
It seems reasonable that the products of an evolutionary process would be both more robust to the changes wrought by evolutionary processes felix2006robustness, and more amenable to improvement through these processes crombach2008evolvability. If these results generalize to software, then software artifacts programmed using evolutionary technique would be expected to be more robust (both mutationally and environmentally) than engineered software artifacts. I propose to test this hypothesis by comparing three types of software artifacts.
- Those programmed entirely by human engineers.
- Those programmed initially by human engineers and then incrementally evolved.
- Those programmed principally through an evolutionary process.
Given that the third type of software to be examined requires de novo evolution, it will likely be necessary to restrict our investigation to the relatively simple languages and algorithms amenable to development through exclusively evolutionary processes.
If it is the case that an evolutionary provenance increases software robustness, then our work may point towards the possibility of using evolution to enhance and replace components of existing engineered systems, as a means of increasing both mutational and environment robustness, as well as the ability of such systems to be improved and repaired through environmental processes.
3.3 Correlates of Mutational Robustness
Having investigated the possible causes of mutational robustness in software I will look to possible effects or correlates of mutational robustness in software. Specifically I propose to study the relation between mutational robustness and evolvability of software, and the relation between mutational and environmental robustness.
3.3.1 Robustness and Evolvability
In biological systems mutational robustness and evolvability are thought to be inextricably linked. Mutational robustness allows neutral mutations to accrue in a population storing the increased diversity required for large evolutionary breakthroughs wagner2005robustness, wilke01, ofria2008gradual, ciliberti2007innovation, huynen1996smoothness, schuster1994sequences, meyers2005potential. However, excessive mutational robustness renders too many mutations neutral, thus inhibiting evolutionary selection of beneficial mutations.
The tension between these opposing effects has been studied in biological systems wagner2005robustness, wagner2008robustness, lenski2006balancing. I propose to study the effects of varying levels of mutational robustness on the evolvability of software systems.
Such a study may indicate what level of mutational robustness is desirable in software and in which cases increased mutational robustness would be beneficial (e.g., maintaining critical behavior) or detrimental (e.g., in the face of a rapidly changing specification).
Such an experiment requires metrics of evolvability and of mutational robustness. The techniques required to measure mutational robustness are supplied by previous work (Section soft-mut-rb). Measuring evolvability is less straight-forward. Two possible approaches are seeding bugs into software projects and testing their amenability to repair through evolution, and adding test cases for previously unimplemented functionality to software projects, and testing the ability of the software to evolve the newly required functionality. With these metrics in hand, correlations can be measured in existing benchmark suites of software projects.
3.3.2 Mutational and Environmental Robustness
Many biological mechanisms are thought to be common causes of both genetic and environmental robustness. For example, metabolic pathways in biological systems often produce stable output over greatly varying sets of inputs deutscher2006multiple. Such buffering protects these processes from varying levels of inputs whether the cause of the variance is due to mutations elsewhere in the organism or to environmental variation.
I propose to investigate whether mutational robustness is positively correlated with environmental robustness in software. I will define the environmental robustness of software to be its ability to execute successfully in a wide range of computational environments. The computational environment will include inputs to the process (generated using fuzz testing tools), the system resources available to the process (e.g., memory, disk space, open file handles, system threads), as well as the speed and reliability with which system calls are handled.
Two different experiments can be used to test for this correlation.
First, correlation can be measured across multiple extant software artifacts. To ensure comparability of environmental robustness the software artifacts must inhabit the same environment, meaning they must implement the same functionality allowing the use of identical fuzz tests, inputs and test suites. One potential source of such diverse programs implementing a single test suite would be programs implementing widely used standards such as data formats (e.g., JSON or YAML), or communication protocols such as router software. The benchmark set developed for this experiment will be re-used in the investigation of software husbandry (Section husbandry).
Second, using traditional EC methods, I plan to separately evolve variants of existing software for increased mutational and environmental robustness using the program optimization techniques proposed in Section optimization. The mutational robustness of those individuals evolved for environmental robustness can then be measured and compared to the original software, and vice versa.
If desirable properties of software such as environmental robustness and evolvability are found to correlate with mutational robustness, then automated methods of increasing software mutational robustness (demonstrated in preliminary work schulte2012smutationalrobustness) may also be used to increase software environmental robustness and evolvability.
4 Applications of Robustness
This section presents applications of the work described in the previous section. The malleability of software makes plausible a number of techniques for software diversification (Section diversity), optimization (Section optimization) and re-combination (Section husbandry) which would previously have seemed unrealistic. I present experiments designed to gauge the potential of each of these techniques below.
4.1 Software Diversity
Software diversity may be a useful goal in and of itself. It has, for example, been leveraged to improve software reliability through N-version systems chen1978n. I hypothesize that the neutral spaces of software systems could be exploited to generate diverse software variants; a process which when performed by hand can be difficult and often leads to surprisingly similar variants knight1986experimental.
In previous work in this area Zachary Fry used diverse program populations to preemptively repair withheld bugs schulte2012smutationalrobustness. The diverse populations were generated through automated exploration of the neutral space of the original program.
In contrast to the direct benefits of diverse software populations demonstrated by Fry et al., the remainder of this section will explore two methods of leveraging diversity to enhance evolutionary techniques of program development and maintenance. Each technique leverages a different cornerstone of the traditional software development environment — compilers and linkers, and version control systems.
4.1.1 Compilers and Linkers
Any given piece of source code may already be used to generate a number of distinct executing programs. The compilation process determines a number of features of the final executable not fully specified by the source code.
Such divergent expressions of a single piece of source code could be used to seed an evolving population of diverse program variants. The neutral reproduction of such a population could be used to mix and match features between different compiled executables, and may evolve new features through mutation.
I propose to use a variety of distinct compilations to seed an evolutionary process with diverse variants of an input program. This increased diversity could be used to jump-start the production of N-variant systems, to augment the evolutionary program repair process and to provide increase genetic material to the software optimization (Section optimization).
In each case the performance of the evolutionary processes seeded using a single program variant will be compared to the performance when seeded with diverse program compilations. This comparison should indicate if increased diversity software improves population evolvability in software systems as it does in biological systems wagner2008robustness.
4.1.2 Program Atavism using Version Control
Biological systems retain genetic information encoding previous phenotypes in such a way that the previous phenotype may be accessible through very minor genetic mutations in a process called atavism crombach2008evolvability. I will develop an automated method of program atavism using information stored in version control repositories. Version control information will be encoded into an evolvable representation in such a way that it is not expressed but is easily accessible to GP operators.
Many authors have added memory to EC systems. Their work can be divided into those with implicitly and explicit memory branke1999memory. Implicit memory systems use constructs similar to gene diploidy in which two or more alternatives of a portion of the genome (a gene) are stored and genetic operators may switch which version of the gene is active (dominant). Explicit memory systems maintain a database of whole individuals from previous runs which may be periodically injected back into the population.
The information stored in version control repositories has clear translations to both implicit and explicit memory systems. Individual patches define alternative implementations for specific portions of a program. A version control history may be views as a set of patches, the entirety of which can be stored in a sufficiently large implicit memory program representation. Each particular version in a version control history specifies a whole variant implementation. These implementations can be stored in an explicit memory system and used to seed future populations.
This work will initially focus on implicit memory representations which provide support for non-coding genetic material. Although both implicit and explicit memory systems have only shown clear benefits in dynamic fitness environments branke1999memory, hadad1997supporting, such an atavistic representation should yield a number of benefits particular to the process of bug repair with operators limited to manipulating the genetic material present in the original program:
- Unless bugs are uniformly distributed through the source code, there will exist locations in the code that are prone to buggy behavior. During regular software maintenance such buggy areas are more likely to accrue edits as bug fixes are applied to the code base. I hypothesize that these localized areas with denser edit histories will benefit bug fixing in two ways. First, an increased number of historical alternative implementations will be available for buggy portions of the program. Second, any representation-uniform genetic operators will focus on buggy portions of the code, which will be over-represented due to denser edit histories.
- Through switching on and off large sections of non-coding genetic information single mutation operations will result in large jumps through phenotype space. I hypothesize that these jumps will facilitate the exploratory processes of evolution.
- Expanding the genetic fodder available to the mutation operators expands GP's ability to express new variants.
As proposed in the previous section, I will evaluate the performance of an atavistic program representation through comparison to existing software representations. This will be done by testing their respective abilities to evolve software variants for the purposes of increasing diversity, repairing software defects, and enabling software optimization.
These experiments will be limited to programs which have sizable edit histories and, in the case of program repair, have bugs not fixable through operations on existing program representations. The benchmark suite used by Le Goues et al. legoues2011systematicstudy satisfies both of these requirements and will be used in our experimental evaluation.
4.2 Software Optimization
During compilation and linking, non-functional properties of software such as running time and executable size may be optimized. Techniques for such optimizations have been extensively researched and implementations can be found in many of the cornerstones of modern software development environments such as GCC stallman2003using.
Current techniques rely almost exclusively on operations that can be formally proven to preserve program semantics. Using the much looser test-suite based definition of program behavior described above I hope to evolve neutral program variants not reachable through semantic-preserving operations alone. Some of these semantically neutral variants may have desirable characteristics such as faster running times or lower energy consumption. Multi-objective EC may be used to evolve software variants which are semantically neutral yet optimize such non-functional properties.
Such an evolutionary multi-objective optimization technique has been demonstrated in work by Sitthi-Amorn et al. sitthi2011genetic in which simplified variants of pixel shaders were evolved from an extant original program. I propose an extension of this work to optimization of diverse properties of programs aside from pixel shaders.
Modern system emulators miller2010graphite allow fine-grained monitoring of many aspects of program execution, which may be difficult to predict a-priori, such as energy consumption and communication overhead. I propose to use such a system to evaluate fitness in a multi-objective EC system for software optimization. I hypothesize a number of benefits to such a system:
- Test-suite defined correctness permits more radical program transformations than available to traditional optimization strategies which are limited to formally semantic-preserving transformations.
- Evaluation using a full system emulator enables optimization of software properties not readily predictable through static analysis, such as aspects of performance based on particulars of the hardware including cache sizes or on chip network speeds.
- The use of a multi-objective fitness function provides a natural method for developers to specify priorities for non-functional optimization.
Specifically this investigation will attempt to optimize the parallel fast Fourier transform (FFT) algorithm. This algorithm is of great importance to scientific computation oppenheim1989discrete and it has received much attention and manual optimization duhamel1990fast, frigo1998fftw. Thus, a competitive evolutionarily optimized FFT implementation would be a significant achievement.
4.3 Software Husbandry
The evolution of diverse populations from single programs raises questions of software identity. Earlier proposed work (Section mut-and-env-rb) described the creation of a benchmark suite composed of multiple distinct programs which all conform to the same test suite. Neutral populations evolved from the members of such a benchmark suite would populate different regions of the same test-suite defined neutral space.
It is possible that individuals from these separate regions may be successfully combined to form new hybrid implementations containing genetic material from both ancestor programs. This amounts to asking if the neutral populations derived from the two original programs are members of the same species — abusing the biological definition of the term.
Recombination of programs with no shared ancestry has been observed in the wild in Microsoft word macro viruses bontchev1998macro. The intentional recombination of ancestrally related programs has been performed at the object level foster2010object. In this work Foster and Somayaji were able to link libraries from two different versions of a program to generate a new version exhibiting features of both ancestor versions.
I propose to use the single-test-suite benchmark suite developed in Section mut-and-env-rb to develop related neutral populations. I will then attempt to combine individuals between these neutral populations using existing crossover operations. If effective, I hypothesize that this technique will have a number of practical applications including:
- the transfer of optimizations between distinct software products
- the transfer of functionality between distinct software products
- an automated method of introducing diversity into program populations
Though outside of the scope of this proposal, such a technique may necessitate new legal tools and definitions related to issues of software identity and copyright, and new limits on the use of compiled program binaries.
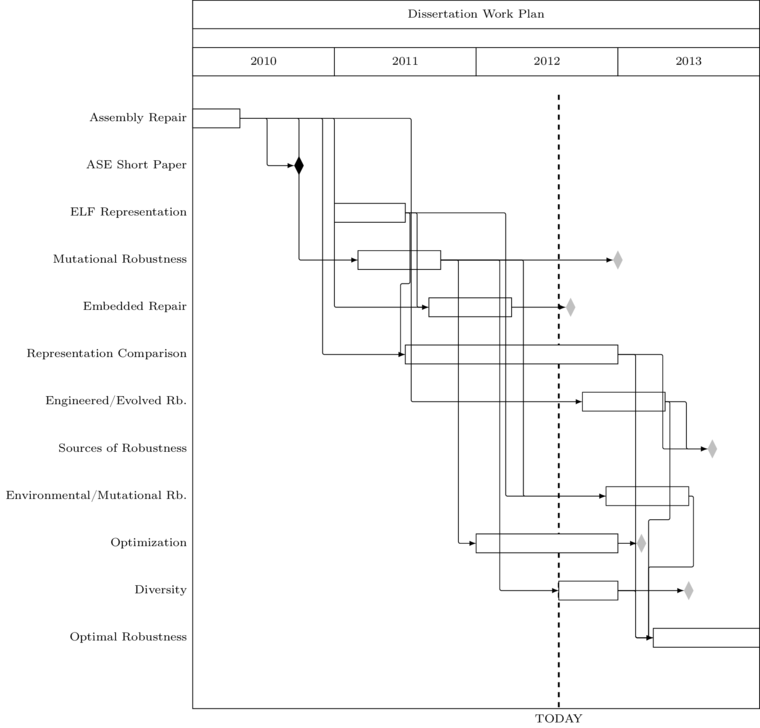
5 Work-plan and Timeline
A detailed work plan is show as a gantt chart in Figure gantt.
6 Conclusion
Engineered software systems are robust in ways previously thought limited to biological systems. I propose an investigation of the robustness of software systems and a number of tools which leverage this robustness.
Our investigation will attempt to isolate the sources of robustness in software, determine the effects of robustness on the evolvability of software, and seek correlations between software robustness and other desirable software properties.
This work presents the modern software development environment as a product of natural selection. A greater understanding of the evolved properties of software will correct errors in existing folk wisdom of software fragility and will improve the ability of software engineers to reason about software performance and to build more effective tools for software development and maintenance.
Footnotes:
1 By pointing out this oversight I do not mean to diminish the importance of the mutation testing community, or its impact on both Software Engineering research and industry practice of the previous 30 years. My work builds upon the existing mutation testing research program and seeks to provide new applications for many existing mutation testing tools, e.g., Compiler-Integrated Techniques demillo1991compiler or super-mutants untch1993mutation could be used to efficiently ship and run entire populations of diverse program variants (Section diversity).