« October 2009 | Main | December 2009 »
November 29, 2009
If you're in Korea this week...
I'm giving three talks, while I'm here visiting Petter Holme. The last time I was in Korea was back in 2007, to visit Hawoong Jeong. I'll have less time for sight seeing, but I'm happy to say that I'll have more than 2 hours between walking off the plane and giving my talk this time (which was entirely my fault last time).
The first is at Sungkyunkwan University (Suwon campus), Monday Nov. 30th (at 16h00; email Petter for details). The second is at Seoul National University on Wednesday Dec. 2nd (also at 16h00, directly after Petter's talk; contact our host Byungnam Kahng for details), and the third is at KAIST on Thursday Dec. 3rd (not sure when; contact our host Hawoong Jeong for details). I'll be talking about the dynamics of terrorist groups and how the frequency and severity of their attacks evolves over their lifetime.
posted November 29, 2009 05:08 PM in Self Referential | permalink | Comments (0)
November 17, 2009
How big is a whale?
One thing I've been working on recently is a project about whale evolution [1]. Yes, whales, those massive and inscrutable aquatic mammals that are apparently the key to saving the world [2]. They've also been called the poster child of macroevolution, which is why I'm interested in them, due to their being so incredibly different from their closest living cousins, who still have four legs and nostrils on the front of their face.








Part of this project requires understanding something about how whale size (mass) and shape (length) are related. This is because in some cases, it's possible to get a notion of how long a whale is (for example, a long dead one buried in Miocene sediments), but it's generally very hard to estimate how heavy it is. [3]
This goes back to an old question in animal morphology, which is whether size and shape are related geometrically or elastically. That is, if I were to double the mass of an animal, would it change its body shape in all directions at once (geometric) or mainly in one direction (elastic)? For some species, like snakes and cloven-hoofed animals (like cows), change is mostly elastic; they mainly get longer (snakes) or wider (bovids, and, some would argue, humans) as they get bigger.
About a decade ago, Marina Silva [4], building on earlier work [5], tackled this question quantitatively for about 30% of all mammal species and, unsurprisingly I think, showed that mammals tend grow geometrically as they change size. In short, yes, mammals are generally spheroids, and L = (const.) x M^(1/3). This model is supposed to be even better for whales: because they're basically neutrally buoyant in water, gravity plays very little role in constraining their shape, and thus there's less reason for them to deviate from the geometric model [6].
Collecting data from primary sources on the length and mass of living whale species, I decided to reproduce Silva's analysis [7]. In this case, I'm using about 2.5 times as much data as Silva had (n=31 species versus n=77 species), so presumably my results are more accurate. Here's a plot of log mass versus log length, which shows a pretty nice allometric scaling relationship between mass (in grams) and length (in meters):
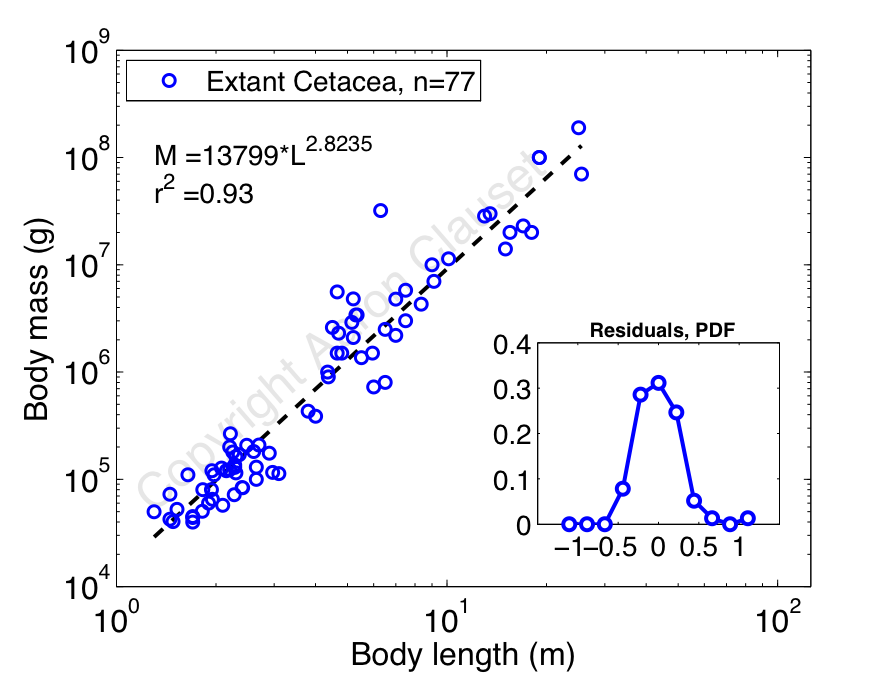
Aside from the fact that mass and length relate very closely, the most interesting thing here is that the estimated scaling exponent is less than 3. If we take the geometric model at face value, then we'd expect the mass of a whole whale to simply be its volume times its density, or
where k_1 and k_2 scale the lengths of the two minor axes (its widths, front-to-back and left-to-right) relative to the major axis (its length L, nose-to-tail), and the trailing constant is the density of whale flesh (here, assumed to be the density of water) [8].
If the constants k_1 and k_2 are the same for all whales (the simplest geometric model), then we'd expect a cubic relation: M = (const.) x L^3. But, our measured exponent is less than 3. So, this implies that k_1 and k_2 cannot be constants, and must instead increase slightly with greater length L. Thus, as a whale gets longer, it gets wider less quickly than we expect from simple geometric scaling. But, that being said, we can't completely rule out the hypothesis that the scatter around the regression line is obscuring a beautifully simple cubic relation, since the 95% confidence intervals around the scaling exponent do actually include 3, but just barely: (2.64, 3.01).
So, the evidence is definitely in the direction of a geometric relationship between a whale's mass and length. That is, to a large extent, a blue whale, which can be 80 feet long (25m), is just a really(!) big bottlenose dolphin, which are usually only 9 feet long (2.9m). That being said, the support for the most simplistic model, i.e., strict geometric scaling with constant k_1 and k_2, is marginal. Instead, something slightly more complicated happens, with a whale's circumference growing more slowly than we'd expect. This kind of behavior could be caused by a mild pressure toward more hydrodynamic forms over the simple geometric forms, since the drag on a longer body should be slightly lower than the drag on a wider body.
Figuring out if that's really the case, though, is beyond me (since I don't know anything about hydrodynamics and drag) and the scope of the project. Instead, it's enough to be able to make a relatively accurate estimation of body mass M from an estimate of body length L. Plus, it's fun to know that big whales are mostly just scaled up versions of little ones.
More about why exactly I need estimates of body mass for will have to wait for another day.
Update 17 Nov. 2009: Changed the 95% CI to 3 significant digits; tip to Cosma.
Update 29 Nov. 2009: Carl Zimmer, one of my favorite science writers, has a nice little post about the way fin whales eat. (Fin whales are almost as large as blue whales, so presumably the mechanics are much the same for blue whales.) It's a fascinating piece, involving the physics of parachutes.
-----
[0] The pictures are, left-to-right, top-to-bottom: blue whale, bottlenose dolphin, humpback whale, sperm whale, beluga, narwhal, Amazon river dolphin, and killer whale.
[1] Actually, I mean Cetaceans, but to keep things simple, I'll refer to whales, dolphins, and porpoises as "whales".
[2] Thankfully, the project doesn't involve networks of whales... If that sounds exciting, try this: D. Lusseau et al. "The bottlenose dolphin community of Doubtful Sound features a large proportion of long-lasting associations. Can geographic isolation explain this unique trait?" Behavioral Ecology and Sociobiology 54(4): 396-405 (2003).
[3] For a terrestrial mammal, it's possible to estimate body size from the shape of its teeth. Basically, mammalian teeth (unlike reptilian teeth) are highly differentiated and certain aspects of their shape correlate strongly with body mass. So, if you happen to find the first molar of a long dead terrestrial mammal, there's a biologist somewhere out there who can tell you both how much it weighed and what it probably ate, even if the tooth is the only thing you have. Much of what we know about mammals from the Jurassic and Triassic, when dinosaurs were dominant, is derived from fossilized teeth rather than full skeletons.
[4] Silva, "Allometric scaling of body length: Elastic or geometric similarity in mammalian design." J. Mammology 79, 20-32 (1998).
[5] Economos, "Elastic and/or geometric similarity in mammalian design?" J. Theoretical Biology 103, 167-172 (1983).
[6] Of course, fully aquatic species may face other biomechanical constraints, due to the drag that water exerts on whales as they move.
[7] Actually, I did the analysis first and then stumbled across her paper, discovering that I'd been scooped more than a decade ago. Still, it's nice to know that this has been looked at before, and that similar conclusions were arrived at.
[8] Blubber has a slight positive buoyancy, and bone has a negative buoyancy, so this value should be pretty close to the true average density of a whale.
posted November 17, 2009 04:33 PM in Evolution | permalink | Comments (2)
November 12, 2009
Power laws and all that jazz, redux
Long time readers will be very familiar with my interest in power-law distributions (for instance, here and here). So, I'm happy (and relieved) to report that my review article, with Cosma Shalizi and Mark Newman, on methods for fitting and validating power-law distributions in empirical data has finally appeared in print over at SIAM Review. Given that this project started back in late 2004 for me, it's very pleasing to see the finished product in print. This calls for a celebration, for sure.
A. Clauset, C. R. Shalizi and M. E. J. Newman. "Power-law distributions in empirical data." SIAM Review 51(4), 661-703 (2009). (Download the code.)
Power-law distributions occur in many situations of scientific interest and have significant consequences for our understanding of natural and man-made phenomena. Unfortunately, the detection and characterization of power laws is complicated by the large fluctuations that occur in the tail of the distribution -- the part of the distribution representing large but rare events -- and by the difficulty of identifying the range over which power-law behavior holds. Commonly used methods for analyzing power-law data, such as least-squares fitting, can produce substantially inaccurate estimates of parameters for power-law distributions, and even in cases where such methods return accurate answers they are still unsatisfactory because they give no indication of whether the data obey a power law at all. Here we present a principled statistical framework for discerning and quantifying power-law behavior in empirical data. Our approach combines maximum-likelihood fitting methods with goodness-of-fit tests based on the Kolmogorov–Smirnov (KS) statistic and likelihood ratios. We evaluate the effectiveness of the approach with tests on synthetic data and give critical comparisons to previous approaches. We also apply the proposed methods to twenty-four real-world data sets from a range of different disciplines, each of which has been conjectured to follow a power-law distribution. In some cases we find these conjectures to be consistent with the data, while in others the power law is ruled out.
Here's a brief summary of the 24 data sets we looked at, and our conclusions as to how much statistical support there is in the data for them to follow a power-law distribution:
Good:
frequency of words (Zipf's law)
Moderate:
frequency of bird sightings
size of blackouts
book sales
population of US cities
size of religions
severity of inter-state wars
number of citations
papers authored
protein-interaction degree distribution
severity of terrorist attacks
With an exponential cut-off:
size of forest fires
intensity of solar flares
intensity of earthquakes (Gutenberg-Richter law)
popularity of surnames
number of web hits
number of web links, with cut-off
Internet (AS) degree distribution
number of phone calls
size of email address book
number of species per genus
None:
HTTP session sizes
wealth
metabolite degree distribution
posted November 12, 2009 08:19 AM in Complex Systems | permalink | Comments (3)
November 06, 2009
Things to read while the simulator runs; part 8
1.
While chatting with Jake Hofman the other day, he pointed me to some analysis by the Facebook Data Team about the way people use online social networks. One issue that seems to come up pretty regularly with Facebook is how many of your "friends" are "real" in some sense (for instance, this came up on a radio show this morning, and my wife routinely teases me for having nearly 400 "friends" on Facebook).
The answer, according to the Facebook Data Team, is that while it depends on how you define "real," with access to the underlying data, you can pretty clearly see how much interaction actually flows across the different links. One neat thing they found (within a lot of interesting analysis) is that the amount of interaction across all your connections scales up with the number of connections you have. That is, the more friends you have, the more friends you interact with. (It can't be a linear relationship, though, since otherwise, people with 1000s of friends would be spending all of their free time on Facebook... oh wait, some people actually do that.)
2.
A related point that I've found myself discussing several times recently with my elders (some of whom I think are, at some level, alienated and befuddled by computer and Web technology), is whether Facebook (or, technology in general) increases social isolation, and thus is leading to some kind of collapse of civil society. I've argued passionately that it's human nature to be social and thus extremely unlikely that technology alone is having this effect, and that technology instead actually facilitates social interactions, allowing people to be even more social overall (even if they may spend slightly less time face-to-face) than before. Mobile phones are my favorite example of social facilitation, since they allow people to interact with their friends in situations when previously they could not (e.g., standing in line at the bank, walking around town, etc.), even if occasionally it leads to ridiculous situations like two people sitting next to each other, but each texting or talking on their phones with people elsewhere.
And, just in time to bolster my arguments, The Pew Internet and American Life Project released a study this week (also discussed in the NYTimes) showing that technology users are more social than non-technology users, and that other, non-technological trends are to blame for the apparent decrease in the size of (non-technology using) Americans' social circles over the past 20 years. Of course, access to and use of technology often correlates with affluence, so what really might be going on is that, like with nutrition, the affluent are better positioned to lead physically and socially healthy lives than the poor.
3.
Recently, for a project on evolution, I've been reading pretty deeply in the paleontology and marine mammal literature (more on that in the next post). The first thing that I noticed is how easy it is now to access vast amounts of scientific literature from the comfort of your office. Occasionally, I had to get up to see Margaret, our librarian, but most of the time I could get what I needed through electronic access. But, sometimes I would encounter a pay wall that my institutional access wouldn't allow me to circumvent.
At first, it was extremely irritating and induced open-access revolutionary spirits in me. Then, I did what I suspect many of you have done, too, which is to ask my friends at other universities to try to get access to the paper using their institutional access, and to send me a copy. On a small scale, this is like asking your friends to share individual musical tracks with you. So, naturally, the logical solution to the problem is to make a P2P sharing system for scientific papers, right? Exactly. There's apparently already such a system for mainly medical papers, but I think the time is ripe for something more ambitious. Given what's been learned about how to run a good P2P system for music, it should be pretty simple to develop a good system (distributed, searchable, scalable) for sharing PDFs of journal papers, right? I can't wait until the academic publishing industry starts suing researchers for sharing papers...
4.
If you're male, when you use a public restroom, what do you think about for those seconds while your body is busy but your mind is free to wander? Randall Munroe, of xkcd fame, apparently, thinks about the mathematics of restroom awkwardness and minimum awkward-ness packing arrangements for men using urinals. Who knew something so mundane could be so amusing?
5.
Finally, this next bit is already almost a year old, but it's just so good. Remember last year when the media when predictably bonkers over two studies, by Nicholas Christakis and James Fowler, showing that happiness and obesity were (socially) contagious? That is, if you're depressed, you can blame your friends for not cheering you up, and if you're fat, you can blame your friends for making you eat poorly. (Or, wait, maybe it's that misery loves company...?) Shortly after those studies hit the media, a wonderful followup study was published by Cohen-Cole and Fletcher. Their study used the same techniques as Christakis and Fowler and showed that acne, headaches and height are also socially contagious! If only we had the data, I'm sure social network analysis could be show that hair color, IQ and wealth are socially contagious, too. Their concluding thoughts say it all, really:
There is a need for caution when attributing causality to correlations in health outcomes between friends using non-experimental data. Confounding is only one of many empirical challenges to estimating social network effects, but researchers do need to attempt to minimise its impact. Thus, while it will probably not be harmful for policy makers and clinicians to attempt to use social networks to spread the benefits of health interventions and information, the current evidence is not yet strong enough to suggest clear evidence based recommendations. There are many unanswered questions and avenues for future research, including use of more robust empirical methods to assess social network effects, crafting and implementing additional empirical solutions to the many difficulties with this research, and further understanding of how social networks are formed and operate.
E. Cohen-Cole and J. M. Fletcher, "Detecting implausible social network effects in acne, height, and headaches: longitudinal analysis." BMJ 337, a2533 (2008).
Update 10 Nov.: Oh jeez. Olivia Judson, please get a clue.
posted November 6, 2009 08:19 AM in Things to Read | permalink | Comments (4)
November 03, 2009
The trouble with community detection
I'm a little (a month!) late in posting it, but here's a new paper, largely by my summer student Ben Good, about the trouble with community detection algorithms.
The short story is that the popular quality function called "modularity" (invented by Mark Newman and Michelle Girvan) admits serious degeneracies that make it somewhat impractical to use in situations where the network is large or has a non-trivial number of communities (a.k.a. modules). At the end of the paper, we briefly survey some ways to potentially mitigate this problem in practical contexts.
The performance of modularity maximization in practical contexts
Benjamin H. Good, Yves-Alexandre de Montjoye, Aaron Clauset, arxiv:0910.0165 (2009).
Although widely used in practice, the behavior and accuracy of the popular module identification technique called modularity maximization is not well understood. Here, we present a broad and systematic characterization of its performance in practical situations. First, we generalize and clarify the recently identified resolution limit phenomenon. Second, we show that the modularity function Q exhibits extreme degeneracies: that is, the modularity landscape admits an exponential number of distinct high-scoring solutions and does not typically exhibit a clear global maximum. Third, we derive the limiting behavior of the maximum modularity Q_max for infinitely modular networks, showing that it depends strongly on the size of the network and the number of module-like subgraphs it contains. Finally, using three real-world examples of metabolic networks, we show that the degenerate solutions can fundamentally disagree on the composition of even the largest modules. Together, these results significantly extend and clarify our understanding of this popular method. In particular, they explain why so many heuristics perform well in practice at finding high-scoring partitions, why these heuristics can disagree on the composition of the identified modules, and how the estimated value of Q_max should be interpreted. Further, they imply that the output of any modularity maximization procedure should be interpreted cautiously in scientific contexts. We conclude by discussing avenues for mitigating these behaviors, such as combining information from many degenerate solutions or using generative models.
posted November 3, 2009 08:55 AM in Networks | permalink | Comments (0)