December 27, 2016
2016: a year in review
This is it for the year. Here's a look back at my 2016, by the numbers [1]:
Papers published or accepted: 4 (journals or equivalent)
Number that were "gold" open access: 2
Number coauthored with students: 2
Cumulative fraction of my papers available online, for free: 0.91 (+0.04 over 2015)
Pre-prints posted on the arxiv or biorxiv: 7
Other publications: 1 invited Perspective in Science (due out in early 2017)
Papers currently under review: 4
Manuscripts near completion: 6
Rejections: 1 (-87% over 2015)
Number of papers making up those rejections: 1
New citations to past papers: 2347 (+18% over 2015)
Projects in-the-works: too many to count
Half-baked projects unlikely to be completed: already forgotten
Oldest project I still intend to finish: project started in 2009
Oldest project completed this year: project started in 2013 (progress!)
Papers read: >132 (about 2.5 per week)
Number of open browser tabs containing papers to read, right now: 17
Number of Dropbox folders created for research projects: 6
Fancy prizes won: 1 (in network science; I am humbled) [2]
Research talks given: 13
Invited talks: 13
Visitors hosted: 4
Conferences, workshops organized: 2
Conferences, workshops, summer schools attended: 4
Number of those at which I delivered a research talk: 4
Number of times other people have written about my research: >14 (mostly about faculty hiring networks and gender)
Coolest external mention of my research: this, in an OSTP presentation at the White House (around the 1h35 mark)
Number of interviews given about my research: 3
Coolest interview: for a British TV science documentary (due out in 2017)
Postdocs advised: 0
Students advised: 11 (8 PhD, 2 MS, 1 BS; 2 rotation students)
Students graduated: 1
Thesis/dissertation committees: 10
Number of recommendation letters written: 13 (+30% over 2015)
Number of those that were for a tenure case: 1
Summer school faculty positions: 1
"Short" courses taught: 2 (both on networks)
University courses taught: 2
Students enrolled in said courses: 51 (15 undergrads and 35 grads)
Number of problems assigned: 73
Number of pages of lecture notes written: pleasantly few
Pages of student work graded: >3069 (roughly 60 per student, with 0.04 graders per student)
Number of class-related emails received: >1320 (+230% over 2015)
Number of instances of stupid plagiarism: 2
Journals for which I am an associate editor: 2 (same as 2015)
Manuscripts handled as an associate editor: 44 (+63% over 2015)
Manuscripts refereed for various journals and journal-equivalent conferences: 13 (-13% over 2015)
Number of those mainly refereed by my students and postdocs: 5
Manuscripts or abstracts lightly refereed for workshops and non-CS conferences: 57 (-32% over 2015)
Conference program committees: 5
Fields covered in my reviewing: Network Science, Computer Science, Physics, Computational Social Science, Social Science, and Physics
Words written per referee report: 502 (-31% over 2015)
Referee requests declined: 69 (-10% over 2015)
Journal I declined the most: Physica A (7 declines, 0 accepts because; the winner by a large margin)
Program committee invitations declined: 4
Number of referee reports I owe anyone, right now: 0
Number of NSF panels I sat on: 1
Number of NSF panels I declined: 3
Grant proposals reviewed: 9 (-40% over 2015)
Fraction that I thought deserved to be funded: 0.50
Fraction that were, I believe, actually funded: <0.20
Grant proposals submitted (as PI or coPI): 4 (totaling $2,249,999)
Number on which I was PI: 3
Proposals rejected: 3
New grants funded: 1 (totaling $550,000)
Proposals pending: 0
New proposals in the works: 2
Emails sent: >10281 (+13% over 2015; about 28 per day)
Emails received (non-spam): >18,854 (+2% over 2015; about 52 per day)
Fraction about work-related topics: 0.93 (+0.02 over 2015)
Fraction that was spam from my university: 0.03 (-0.01 over 2015)
Fraction about research funding: 0.08
Emails received about power-law distributions: >109 (about 2 per week)
Number of emails in my inbox, right now: 22 (+5% over 2015)
Oldest-dated email in my inbox, right now: July 2011 (I am ashamed)
Unique visitors to my professional homepage: 27,500 (-8% over 2015)
Hits overall: 81,000 (+4% over 2015)
Fraction of visitors looking for power-law distributions: 0.40 (+0.02 over 2015)
Fraction of visitors looking for my course materials: 0.21 (-0.07 over 2015)
Unique visitors to my blog: 6,500 (+14% over 2015)
Hits overall: 10,700 (+19% over 2015)
Most popular blog post among those visitors: The trouble with modern interdisciplinary publishing (from 2016)
Blog posts written: 2 (+0% over 2015)
Blog posts conceived but never written down: 2 (I think?)
Number of twitter accounts: 1
New followers on Twitter: >817 (+25% over 2015)
New tweets: 59 (-71% over 2015)
Retweets of my tweets: 1036 (-6% over 2015)
Average number of retweets per original tweet: 17.6 (+97% over 2015)
Most popular tweet: one about David Hu's 'confessions' as a scientist
Number of computers purchased: 0
Number of cars purchased: 0
Netflix: too many to count
Books purchased: 3 (-25% over 2015)
Books read: 2 (-50% over 2015)
Songs added to music library: 49 (-91% over 2015)
Photos added to photo library: 1983 (+20% over 2015)
Photos taken of my daughters: >1520 (about 4 per day)
Jigsaw puzzle pieces assembled: <1000
Major life / career changes / decisions: 0
Number of offspring: 2 (+0% over 2015)
Fun trips with friends / family: 7
Half-marathons completed: 0
Steps this year: >1,624,615 (about 4500/day, and -25% over 2015 [3])
Walking distance this year: 803 miles (a very bursty average of 2.2/day)
Trips to Las Vegas, NV: 0
Trips to New York, NY: 0
Trips to Santa Fe, NM: 5
States in the US visited: 7 (CA, FL, GA, IA, NC, NM, TX)
States in the US visited, ever: 49
Foreign countries visited: 2 (Korea, United Kingdom)
Foreign countries visited, ever: 31 (+0% over 2015)
Other continents visited: 2
Other continents visited, ever: 5
Airplane flights: 33 (+43% over 2015)
Here's to a great year, and hoping that 2017 is even better.
-----
[1] This is where I put my now annual acknowledgement that I don't post much on this blog anymore. This continues to be mainly because of being busy with other things, some fun and some tedious, that come with being a university professor, and with having a family. But, as I've said in past years, I still like the idea of having a blog, where I can write things that are too long for Twitter, but too informal for an academic paper. However, it does seem that it's time for me to relocate this blog to another place, and set the CS Department at the University of New Mexico free of the burden of running its server.
[2] It's not a fancy prize, but I am nonetheless humbled that someone has created an official Wikipedia page for me.
[3] Apparently, I walked a lot more when I was on paternity leave, last year.
posted December 27, 2016 04:07 AM in Self Referential | permalink | Comments (2)
December 26, 2015
2015: a year in review
This is it for the year. Here's a look back at my 2015, by the numbers [1,2]:
Papers published or accepted: 8 (journals or equivalent)
Number that were "gold" open access: 2
Number coauthored with students: 4
Number that used data from sports: 2, again (this and that)
Cumulative fraction of my papers available online, for free: 0.87 (+0.21 over 2014)
Pre-prints posted on the arxiv: 7
Other publications: 1 perspective piece, and 1 popular press piece
Number of those coauthored with students: 1
Papers currently under review: 4
Manuscripts near completion: 5
Rejections: 7 (+17% over 2014)
Number of papers making up those rejections: 6
New citations to past papers: 1981 (+1.1% over 2014)
Projects in-the-works: too many to count
Half-baked projects unlikely to be completed: already forgotten
Papers read: >114 (about 2 per week)
Number of open browser tabs containing papers to read, right now: 9
Number of Dropbox folders created for research projects: 4
Research talks given: 6
Invited talks: 6
Visitors hosted: 5
Conferences, workshops organized: 3
Conferences, workshops, summer schools attended: 9
Number of those at which I delivered a research talk: 4
Number of times other people have written about my research: >42 (mostly about faculty hiring networks)
Number of interviews given about my research: 18
Coolest interview: for Double Helix, an Australian children's science magazine
Postdocs advised: 3
Students advised: 11 (5 PhD, 1 MS, 3 BS; 2 rotation students)
Students graduated: 1
Thesis/dissertation committees: 4
Number of recommendation letters written: 10
Summer school faculty positions: 1, in India (technically a "winter school")
"Short" courses taught: 2 (both on networks)
University courses taught: 1 (this one)
Students enrolled in said courses: 11 undergrads
Number of problems assigned: 23 (weekly essays, plus two essay exams)
Number of pages of lecture notes written: pleasantly few
Pages of student work graded: >390 (roughly 36 per undergrad, with 0.09 graders per student)
Number of class-related emails received: >400 (-86% over 2014)
Number of conversations with the university honor council: 0
Journals for which I am an associate editor: 2 (same as 2014)
Manuscripts handled as an associate editor: 27 (+450% over 2014)
Manuscripts refereed for various journals and journal-equivalent conferences: 15 (-44% over 2014)
Number of those mainly refereed by my students and postdocs: 8
Manuscripts or abstracts lightly refereed for workshops and non-CS conferences: 84
Conference program committees: 4
Fields covered: Network Science, Computer Science, Statistics, Physics, and some tabloids
Words written per referee report: 729 (-45% over 2014)
Referee requests declined: 77 (+4% over 2014)
Journal I declined the most: Scientific Reports (10 declines, 0 accepts; just edging out Physica A)
Program committee invitations declined: 4
Number of referee reports I owe anyone, right now: 0
Number of NSF panels I sat on: 2
Grant proposals reviewed: 15
Fraction that I thought deserved to be funded: 0.50
Fraction that were, I believe, actually funded: <0.20
Grant proposals submitted or reviewed (as PI or coPI): 7 (totaling $34,257,680)
Number on which I was PI: 2
Proposals rejected: 5
New grants funded: 2 (totaling $600,014)
Proposals pending: 1
New proposals in the works: 2
Emails sent: >9104 (-2% over 2014; about 25 per day)
Emails received (non-spam): >18,403 (-8% over 2014; about 50 per day)
Fraction about work-related topics: 0.91 (+0.01 over 2014)
Fraction that was spam from my university: 0.04 (+7% over 2014)
Fraction about research funding: 0.07
Emails received about power-law distributions: >94 (about 2 per week)
Number of emails in my inbox, right now: 21
Oldest-dated email in my inbox, right now: November 2010 (I am ashamed)
Unique visitors to my professional homepage: 30,000 (+3% over 2014)
Hits overall: 78,000 (-17% over 2014)
Fraction of visitors looking for power-law distributions: 0.38 (-0.01 over 2014)
Fraction of visitors looking for my course materials: 0.28 (+0.04 over 2014)
Unique visitors to my blog: 5,700 (-21% over 2014)
Hits overall: 9,000 (-29% over 2014)
Most popular blog post among those visitors: A "reverse" color test (from 2006)
Blog posts written: 2 (-70% over 2014)
Blog posts conceived but never written down: 3 (I think?)
Number of twitter accounts: 1
New followers on Twitter: >653 (-12% over 2014)
Tweets: 202 (-10% over 2014; including retweets of others)
Retweets of my tweets: 1108 (+10% over 2014)
Average number of retweets per original tweet: 8.9 (+31% over 2014)
Fraction of my tweets that are original: 0.62 (-0.04 over 2014)
Most popular tweet: one about NSF requiring articles to be made publicly available within one year of publication
Number of computers purchased: 1
Number of cars purchased: 0
Netflix: too many to count
Books purchased: 4 (-43% over 2014)
Books read: 3 (+0% over 2014)
Songs added to music library: 544 (+435% over 2014)
Photos added to photo library: 1654 (+70% over 2014)
Photos taken of my daughters: >1650 (about 5 per day)
Jigsaw puzzle pieces assembled: 1160
Major life / career changes / decisions: 1
Number of offspring: 2 (+100% over 2014)
Fun trips with friends / family: 7
Half-marathons completed: 0
Steps this year: 2,169,560 (about 6000 per day)
Walking distance this year: 1201 miles (about 3.3 per day, but it's very bursty)
Trips to Las Vegas, NV: 0
Trips to New York, NY: 0
Trips to Santa Fe, NM: 6
States in the US visited: 5 (TX, NM, CA, TN, AZ)
States in the US visited, ever: 49
Foreign countries visited: 2 (Spain, India)
Foreign countries visited, ever: 31 (+3% over 2014)
Other continents visited: 2
Other continents visited, ever: 5
Airplane flights: 23 (-48% over 2014)
Here's to a great year, and hoping that 2016 is even better.
-----
[1] I am shocked to learn that some people actually look forward to my year-by-the-numbers post.
[2] It is hard to ignore the fact that I don't post much here anymore. This is partly because of being busy with other things, some fun and some tedious, that come with being a university professor, and with having a family. I also now post many of the things that I read and find interesting on Twitter, which people seem to like. That said, I still like the idea of having a blog, where I can write things that are too long for Twitter, but too informal for an academic paper. So, as long as the CS Department at the University of New Mexico keeps the servers running the blog up, I'll keep posting, occasionally. If those servers go down, or if UNM asks me to relocate, I'll have to make a decision about whether it's worth the effort to move it. (I've already looked into it, and it seems... highly non-trivial to move 10 years worth of material to another platform.)
posted December 26, 2015 11:51 AM in Self Referential | permalink | Comments (3)
December 21, 2014
2014: a year in review
This is it for the year, so here's a look back at 2014, by the numbers.
Papers published or accepted: 9 (journals or equivalent)
Number coauthored with students: 5
Number of papers that used data from sports: 2 (this and that)
Pre-prints posted on the arxiv: 5
Other publications: 2 workshop papers, and 1 popular press piece
Number of those coauthored with students: 1
Papers currently under review: 1
Manuscripts near completion: 9
Rejections: 6
Number of papers making up those rejections: 2
New citations to past papers: 1959 (+14% over 2013)
Projects in-the-works: too many to count
Half-baked projects unlikely to be completed: already forgotten
Papers read: >104 (about 2 per week)
Number of open browser tabs containing papers to read, right now: 22
Research talks given: 15
Invited talks: 13
Visitors hosted: 7
Presentations to high school students about science and data: 1 (at Fairview High School in Boulder)
Conferences, workshops organized: 3
Conferences, workshops, summer schools attended: 9
Number of those at which I delivered a research talk: 8
Number of times other people have written about my research: >9
Number of interviews given about my research: 4
Number of times I appeared on the BBC Radio: 1 (here)
Students advised: 11 (6 PhD, 1 MS, 2 BS; 1 rotation student and 1 high school student)
Students graduated: 1 MS
Thesis/dissertation committees: 10
Number of recommendation letters written: 12
Summer school faculty positions: 1
University courses taught: 2
Students enrolled in said courses: 113 undergrad, 32 grad
Number of problems assigned: 121 and 50
Number of pages of lecture notes written: the mind shudders to think
Pages of student work graded: >7500 (roughly 44 per undergrad and 84 per grad student, with 0.02 graders per student)
Number of class-related emails received: >2814 (+73% over 2013)
Number of conversations with the university honor council: 0
Manuscripts handled as an associate editor: 6 (+300% over 2013)
Manuscripts refereed for various journals and journal-equivalent conferences: 27 (+17% over 2013)
Number of those mainly refereed by my students and postdocs: 11
Manuscripts lightly refereed for workshops and non-CS conferences: 45
Conference program committees: 4
Fields covered: Network Science, Machine Learning, Data Science, Ecology, and some tabloids
Words written per referee report: 1333 (+45% over 2013)
Referee requests declined: 74 (+9% over 2013)
Journal I declined the most: Physica A (8 declines, 0 accepts)
Program committee invitations declined: 5
Number of referee reports I owe anyone, right now: 0
Grant proposals submitted (PI or coPI): 10 (totaling $38,227,680)
Number on which I was PI: 4
Proposals rejected: 2
New grants awarded: 2 (totaling $620,000, including my NSF CAREER proposal)
Proposals pending: 6
New proposals in the works: 2
Emails sent: >9325 (+13% over 2013, and about 25 per day)
Emails received (non-spam): >20,026 (+22% over 2013, and about 55 per day)
Fraction about work-related topics: 0.90 (+0.03 over 2013)
Fraction of work-related email about research funding: 0.13
Emails received about power-law distributions: 153 (3 per week, same as 2013)
Number of emails in my inbox, right now: 24
Oldest-dated email in my inbox, right now: November 2010 (I am ashamed)
Unique visitors to my professional homepage: 29,000 (-7% over 2013)
Hits overall: 94,000 (+8% over 2013)
Fraction of visitors looking for power-law distributions: 0.39 (-0.13 over 2013)
Fraction of visitors looking for my course materials: 0.24
Unique visitors to my blog: 7,200 (-36% over 2013)
Hits overall: 12,600 (-27% over 2013)
Most popular blog post among those visitors: The faculty market (Advice to young scholars, part 1 of 4) (from 2014)
Blog posts written: 7 (+17% over 2013)
Number of twitter accounts: 1
New followers on Twitter: >741 (+6% over 2013)
Tweets: 225 (-4% over 2013; including retweets of others)
Retweets of my tweets: 1006 (+8% over 2013)
Average number of retweets per original tweet: 6.8
Fraction of my tweets that are original: 0.66
Most popular tweet: a tweet about there being more annual job openings than graduates for CS and Math majors
K-index: 2.98 (just over half a Kardashian Scientist; whew)
Number of computers purchased: 1
Number of cars purchased: 1
Netflix: <60 dvds, 139 streaming (mostly TV episodes during lunch breaks and nap times)
Books purchased: 7 (+133% over 2013)
Books read: 3 (+0% over 2013)
Songs added to iTunes: 125 (-11% over 2013)
Photos added to iPhoto: 971 (-59% over 2013)
Photos taken of my daughter: >933 (about 3 per day)
Jigsaw puzzle pieces assembled: 0
Major life / career changes / decisions: 2
Fun trips with friends / family: 9
Half-marathons completed: 0
Trips to Las Vegas, NV: 0
Trips to New York, NY: 1
Trips to Santa Fe, NM: 7
States in the US visited: 9 (MA, NY, PA, UT, FL, NM, CA, VA, MI)
States in the US visited, ever: 49
Foreign countries visited: 3 (Germany, China, Canada)
Foreign countries visited, ever: 30
Other continents visited: 2
Other continents visited, ever: 5
Airplane flights: 44 (+13% over 2013)
Here's to a great year, and hoping that 2015 is even better.
posted December 21, 2014 02:28 AM in Self Referential | permalink | Comments (1)
December 22, 2013
2013: a year in review
This is it for the year, so here's a look back at 2013, by the numbers.
Papers published or accepted: 10 (journals or equivalent)
Number coauthored with students: 4
Number of papers that used data from a video game: 3 (this, that, and the other)
Pre-prints posted on the arxiv: 6
Other publications: 2 workshop papers, and 1 invited comment
Number coauthored with students: 2
Papers currently under review: 2
Manuscripts near completion: 8
Rejections: 4
New citations to past papers: 1722 (+15% over 2012)
Projects in-the-works: too many to count
Half-baked projects unlikely to be completed: already forgotten
Papers read: >200 (about 4 per week)
Research talks given: 15
Invited talks: 13
Visitors hosted: 2
Presentations to school teachers about science and data: 1 (at the fabulous Denver Museum of Nature and Science)
Conferences, workshops organized: 2
Conferences, workshops, summer schools attended: 7
Number of those at which I delivered a research talk: 5
Number of times other people have written about my research: >17
Number of interviews given about my research: 10
Students advised: 9 (6 PhD, 1 MS, 1 BS; 1 rotation student)
Students graduated: 1 PhD (my first: Dr. Sears Merritt), 1 MS
Thesis/dissertation committees: 10
Number of recommendation letters written: 5
Summer school faculty positions: 2
University courses taught: 2
Students enrolled in said courses: 69 grad
Number of problems assigned: 120
Number of pages of lecture notes written: >150 (a book, of sorts)
Pages of student work graded: 7225 (roughly 105 per student, with 0.04 graders per student)
Number of class-related emails received: >1624 (+38% over 2012)
Number of conversations with the university honor council: 0
Guest lectures for colleagues: 1
Proposals refereed for grant-making agencies: 1
Manuscripts refereed for various journals, conferences: 23 (+44% over 2012)
Fields covered: Network Science, Computer Science, Machine Learning, Physics, Ecology, Political Science, and some tabloids
Manuscripts edited for various journals: 2
Conference program committees: 2
Words written per report: 921 (-40% over 2012)
Referee requests declined: 68 (+36% over 2012)
Journal I declined the most: PLoS ONE (12 declines, 3 accepts)
Grant proposals submitted: 7 (totaling $6,013,669)
Number on which I was PI: 3
Proposals rejected: 2
New grants awarded: 3 (totaling $1,438,985)
Number on which I was PI: 1
Proposals pending: 2
New proposals in the works: 3
Emails sent: >8269 (+3% over 2012, and about 23 per day)
Emails received (non-spam): >16453 (+6% over 2012, and about 45 per day)
Fraction about work-related topics: 0.87 (-0.02 over 2012)
Emails received about power-law distributions: 157 (3 per week, same as 2012)
Unique visitors to my professional homepage: 31,000 (same as 2012)
Hits overall: 87,000 (+10% over 2012)
Fraction of visitors looking for power-law distributions: 0.52 (-11% over 2012)
Fraction of visitors looking for my course materials: 0.16
Unique visitors to my blog: 11,300 (-2% over 2012)
Hits overall: 17,300 (-4% over 2012)
Most popular blog post among those visitors: Our ignorance of intelligence (from 2005)
Blog posts written: 6 (-57% over 2012)
Most popular 2013 blog post: Small science for the win? Maybe not.
Number of twitter accounts: 1
Tweets: 235 (+82% over 2012; mostly in lieu of blogging)
Retweets: >930 (+281% over 2012)
Most popular tweet: a tweet about professors having little time to think
New followers on Twitter: >700 (+202% over 2012)
Number of computers purchased: 2
Netflix: 72 dvds, >100 instant (mostly TV episodes during lunch breaks and nap times)
Books purchased: 3 (-73% over 2012)
Songs added to iTunes: 140 (-5% over 2012)
Photos added to iPhoto: 2357 (+270% over 2012)
Jigsaw puzzle pieces assembled: >2,000
Major life / career changes: 0
Photos taken of my daughter: >1821 (about 5 per day)
Fun trips with friends / family: 10
Half-marathons completed: 0.76 (Coal Creek Crossing 10 mile race)
Trips to Las Vegas, NV: 0
Trips to New York, NY: 1
Trips to Santa Fe, NM: 9
States in the US visited: 8
States in the US visited, ever: 49
Foreign countries visited: 6 (Switzerland, Denmark, Sweden, Norway, United Kingdom, Canada)
Foreign countries visited, ever: 30
Number of those I drove to: 1 (Canada, 10 hours from Washington DC after United canceled my flight to Montreal for the JSM; I arrived with a few hours to spare before my invited talk)
Other continents visited: 1
Other continents visited, ever: 5
Airplane flights: 39
Here's to a great year, and hoping that 2014 is even better.
Update 23 December 2013: Mason reminded me that I forgot a foreign country this year.
posted December 22, 2013 11:16 PM in Self Referential | permalink | Comments (2)
December 22, 2012
2012: a year in review
This is probably it for the year, so here's a look back at 2012, by the numbers.
Papers published (or accepted): 4 (the pipeline is moving again)
Pre-prints posted on the arxiv: 5
Other publications: 0
Papers currently under review: 3
Manuscripts near completion: 7
Rejections: 9 (includes rejection without review)
New citations to past papers: 1495 (+20% over 2011)
Projects in-the-works: too many to count
Half-baked projects unlikely to be completed: already forgotten
Papers read: >202
Research talks given: 9
Invited talks: 8
Visitors hosted: 1
Conferences, workshops organized: 0
Conferences, workshops, summer schools attended: 4
Number of those at which I delivered a research talk: 3
Number of times other people have written about my research: >11
Number of times Nate Silver wrote about my research: 1 (cool)
Number of interviews about my research: 1
Students advised: 13 (7 PhD, 1 MS, 3 BS; 2 rotation student)
Students graduated: 1 MS
Thesis/dissertation committees: 6
Number of recommendation letters written: 10
Summer school faculty positions: 2
University courses taught: 1 (repeated)
Students enrolled in said courses: 51 grad
Number of problems assigned: 85
Pages of student work graded: 5282 (roughly 103 pages per student, with 2 graders)
Number of class-related emails received: >1174
Number of conversations with the faculty honor council liaison: 0
Guest lectures for colleagues: 0
Proposals refereed for grant-making agencies: 15
Manuscripts refereed for various journals, conferences: 16
Words written in per report: 1528 (average)
Referee requests declined: 50 (-4% over 2011)
Conference program committees: 1
Grant proposals submitted: 6 (totaling $2,212,343)
Proposals rejected: 2
New grants awarded: 3 (totaling $1,379,260)
Proposals pending: 3
New proposals in the works: 2
Emails sent: >8061 (+9% over 2011)
Emails received (non-spam): >15503 (+18% over 2011)
Fraction about work-related topics: 0.89 (same as 2011)
Emails received about power-law distributions: 146 (3 per week)
Unique visitors to professional homepage: 31,000
Hits overall: 79,000
Fraction of visitors looking for power-law distributions: 0.63 (wow)
Unique visitors to blog: 11,500
Hits overall: 18,000
Most popular blog post among those visitors: Our ignorance of intelligence (from 2005)
Blog posts written: 14 (-30% from last year)
Most popular 2012 blog post: A crisis in higher education?
Number of twitter accounts: 1, my first (I blame peer pressure)
Tweets: 129
Retweets: 330ish (remarkably)
New followers on Twitter: >346 (astonishingly)
Number of computers purchased: 1
Movies/shows via Netflix: 32 dvds, 100 instant
Books purchased: 11
Songs added to iTunes: 148
Photos added to iPhoto: 874
Jigsaw puzzle pieces assembled: >5,000
Major life / career changes: 2 (see next two entries)
Houses purchased: 1
Babies: 1, naturally born
Semesters of paternity leave: 1
Photos taken of baby so far: >683 (about 5 per day)
Fun trips with friends / family: 9
Half-marathons completed: 0
Trips to Las Vegas, NV: 1
Trips to New York, NY: 0
Trips to Santa Fe, NM: 7
States visited (in the US): 4
Foreign countries visited: 1 (Germany)
Other continents visited: 1
Airplane flights: 22
Here's to a great year, and hoping that 2013 is even better.
posted December 22, 2012 07:07 PM in Self Referential | permalink | Comments (0)
August 18, 2012
Onward, upward (2012 edition)
Long-time readers will have noticed the distinct lack of blog activity over the past few months. I decided to take the summer off from blogging in order to focus on finishing or pushing along as many projects as possible (like this one, about "How large should whales be?") before the arrival of my daughter Parker Grace Clauset, who was naturally born on 31 July 2012. I am very proud of her momma and am excited to embark on this new and profound journey. Regular blogging will resume shortly.
posted August 18, 2012 11:29 AM in Self Referential | permalink | Comments (0)
March 19, 2012
Oops, I tweeted again
After some peer pressure from friends, I've signed up for twitter. This will be a purely professional account, focusing on science and research. If you're into that kind of thing, you can follow me @aaronclauset.
posted March 19, 2012 08:59 AM in Self Referential | permalink | Comments (0)
March 15, 2012
Milestone
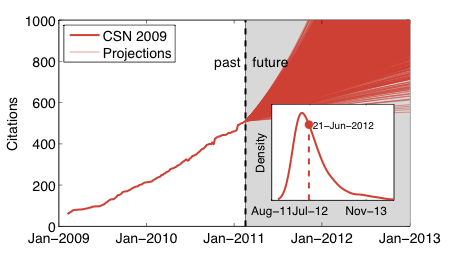
Today is a milestone. About a year ago, I blogged about the meteoric rate that my paper with Cosma Shalizi and Mark Newman, on power-law distributions in empirical data, was collecting citations. On that day, the paper had just crossed 500 Google Scholar citations and I used that milestone as an excuse to ask when it might cross the mind-boggling 1000 citations. [1] Since we know a thing or two about citation counts, I decide to apply a little model-based statistical forecasting to come up with a principled guess.
This produced a probability distribution of answers, with the modal crossing date among all the bootstrap models being 21 April 2012 (the 90% bootstrap confidence intervals were 11 Jan. 2012 to 29 Nov. 2013, but the bulk of the distribution is centered on Spring 2012). And, to my surprise and great amusement, 15 March 2012 was the actual crossing date, only a month off from the prediction. Here's what the forecasts from a year ago looked like, along with the actual citation data overlaid. I've also marked where on the forecast distribution the actual prediction landed.
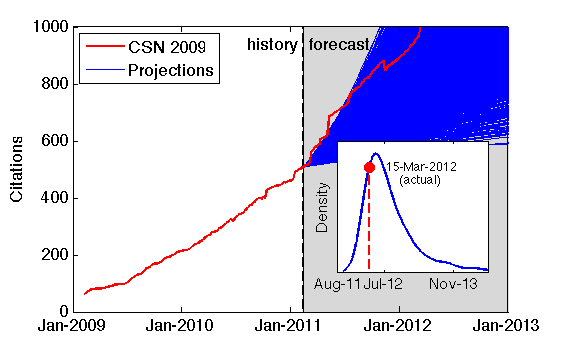
In the new citation data, we again see strange drops and jumps in the citation count. These are presumably from the Google Scholar team tinkering with their algorithms. In fact, the crossing today was caused by the sudden appearance of 44 new citations in the past 5 days, which is high above the normal accumulation rate. But, this may have been a change to the algorithm that restored the citations misplaced in the large drop that occurred in late 2011, it seems reasonable to treat this as a real event. Either way, the closeness of the true crossing data to the forecasted one is a little eerie.
So, there you have it. A milestone. Huzzah. Perhaps I'll buy a mug to commemorate the event.
-----
[1] It is worth saying that the popularity of this paper has been both pleasantly surprising, and gratifying, and I am immensely grateful for what great collaborators Cosma and Mark were on the paper.
posted March 15, 2012 05:17 PM in Self Referential | permalink | Comments (4)
December 24, 2011
2011: a year in review
This is probably it for the year, so here's a look back at 2011, by the numbers.
Papers published (or accepted): 0
Other publications: 1 tech report
Papers currently under review: 3 (including my first with a CU student)
Manuscripts near completion: 5
New citations to past papers: 1250
Projects in-the-works: too many to count
Half-baked projects unlikely to be completed: already forgotten
Papers read: >579
Research talks given: 13
Invited talks: 8
Visitors hosted: 3
Conferences, workshops organized: 0
Conferences, workshops, summer schools attended: 7
Number of those at which I delivered a research talk: 7
Number of times other people have written about my research: >8
Number of interviews about my research: 7
Number of times featured in a brief to SCOTUS: 1 (cool)
Students advised: 10 (4 PhD, 1 MS, 4 BS; 1 rotation student)
Students graduated: 0
Thesis/dissertation committees: 6
Summer school faculty positions: 1
University courses taught: 2 (1 new, 1 repeated)
Students enrolled in said courses: 31 grad, 1 undergrad
Pages of new lecture notes written for said courses: >137
Number of problems assigned: 96
Pages of new solutions written for said problems: 49
Pages of student work graded: 2046 (roughly 64 pages per student)
Number of class-related emails received: >818
Number of conversations with the faculty honor council liaison: 0 (an improvement)
Guest lectures for colleagues: 2
Number of recommendation letters: 6 (students)
Manuscripts refereed for various journals, conferences: >22
Words written in those reports: >16000
Referee requests declined: >53
Program committees: 1
Film deals declined: 1
Grant proposals submitted: 12 (up from last year; totaling $7,693,264)
Grants awarded: 0
Grant proposals pending: 3
New proposals in the works: 4
Emails sent: >7387 (+50% more than last year)
Emails received (non-spam): >13122 (+40% more than last year)
Fraction about work-related topics: 0.89
Number of computers purchased: 1
Blog entries written: 20 (way down from last year)
Movies/shows via Netflix: 24 dvds, 100 instant
Books purchased: 15
Songs added to iTunes: 175
Photos added to iPhoto: 512
Jigsaw puzzle pieces assembled: >10,000
Major life / career changes: 0
Fun trips with friends / family: 6
Half-marathons completed: 1
Trips to Las Vegas, NV: 0
Trips to New York, NY: 0
Trips to Santa Fe, NM: 7
States visited (in the US): 7
Foreign countries visited: 4 (Canada, Sweden, Italy, Switzerland)
Other continents visited: 1
Airplane flights: 24 (direct flights are great)
Total flight miles: 39000 (60% of 2010)
Here's to a great year, and hoping that 2012 is just as good. (Although maybe with a few more papers published...)
posted December 24, 2011 11:06 AM in Self Referential | permalink | Comments (5)
February 18, 2011
1000 Citations?
Today I'm going to admit something embarrassing, but something I suspect many academics do, especially now that it's so easy: I track my citation counts. It's always nice to see the numbers increase, but it also lets me keep up with which communities are reading my papers. Naturally, some papers do much better than others in picking up citations [1]. One that's been surprisingly successful is my paper with Cosma Shalizi and Mark Newman on power-law distributions in empirical data [2], which crossed 500 citations on Google Scholar earlier this year. Here's what the citation time series looks like [3]:
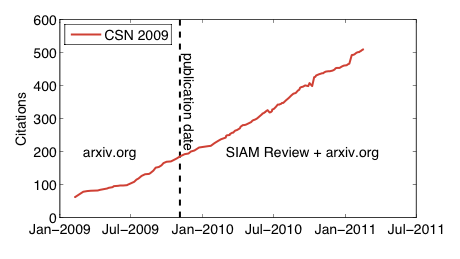
I've marked the online publication date (4 November 2009) in SIAM Review in the figure with the black dashed line. Notably, the trajectory seems completely unperturbed by this event, suggesting that perhaps most people who were finding the paper, were finding it through the arxiv, where it was posted in October 2007.
Given its already enormous citation count, with this data in hand, can we predict when it will pass the mind-boggling 1000 citation mark? The answer is yes, although we'll have to wait to see if the prediction is correct. [4]
Derek de Solla Price, the father of modern bibliometrics and the original discoverer of the preferential attachment mechanism for citation networks, tells us that the growth rate of citations is proportional to the number of citations a paper already has. Testing this assumption is trickier than it sounds. At the whole-citation-network level, the prediction of this assumption is a distribution of citations that has a power-law tail [5]. There have been a few attempts to test the microscopic assumption itself, again on a corpus of papers, and one of my favorites is in a 2005 paper in Physics Today by Sid Redner [6]. Redner analyzed 110 years of citation statistics from the Physical Review journals, and he calculated the attachment rates for groups of papers by first counting all the citations they received in some window of time [t,t+dt] and then counting the number of citations each of those papers received in a given subsequent year T. He then plotted the new citations in year T versus the total citations in the window, and observed that the function was remarkably linear, indicating that the proportional attachment assumption is actually pretty reasonable.
But, I haven't seen anyone try to test the proportional growth assumption on an individual paper, and perhaps for good reason. The model is grossly simplified: it ignores factors like the quality or importance of the paper, the fame of the authors, the fame of the journal, the influence of the peer review process, the paper’s topic, etc. In fact, the model ignores everything about the papers themselves except for its citation count. If we consider very many papers, it seems potentially plausible that these things should average out in some way. But for a single paper, surely these factors are important.
Maybe, but let's ignore them for now. For the CSN_2009 paper, let's mimic what Redner did to estimate the attachment rate: we choose some window length dt, divide up the 739 days of data into blocks each of dt days, and plot the number of citations at the beginning of a window versus the number of new citations the paper acquires over the next dt days. Here's the result, for a window length of 20 days:
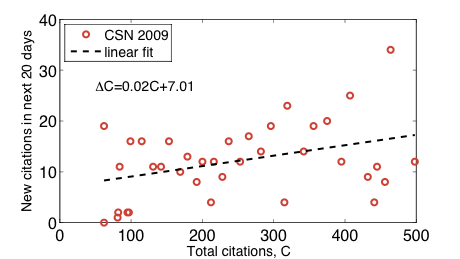
along with a simple linear fit to the scatter. Surprisingly, the positive slope suggests that the citation rate has indeed been increasing (roughly linearly) with total citation count, which in turn suggests that proportional growth is potentially a reasonable model of the citation history of this one specific paper. It also suggests that people are citing our paper not because it's a good paper, but because it's a highly cited paper. After all, proportional growth is a model of popularity not quality. (Actually, the very small value of the coefficient suggests that this might be a spurious result; see [7] below.)
This linear fit to the attachment rates is, effectively, a parametric proportional growth model, i.e., the coefficients allow us to estimate the number of new citations the paper will acquire in the next 20 days, as a function of the current citation count. Integrating this attachment rate over time allows us to make a projection of the paper's citation trajectory, which allows us to predict the date at which the paper will cross 1000 citations. Since the window size dt is an arbitrary parameter, and it's not at all clear how to choose the best value for it, instead we'll just make a set of projections, one for each value of dt. Here's the result:
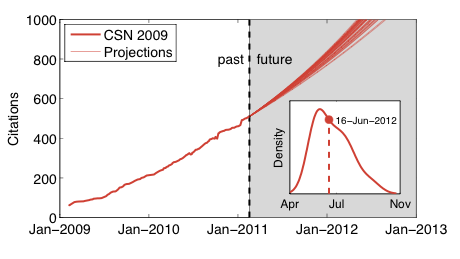
with the inset showing the smoothed distribution of predicted dates that the citation count will cross 1000. All of the predicted crossing dates fall in 2012, but vary based on the different fitted attachment rate models. The median date is 16 June 2012, which is slightly later than the mode at 29 May (this seems reasonable given the non-linear nature of the growth model); the 5 and 95% quantiles are at 1 May and 31 August.
So, there you have it, a prediction that CSN_2009 will cross 1000 citations in 14-18 months, and most likely in 15-16 months. [7] If I'm right, someone want to buy me a beer (or maybe a mug) to celebrate?
Update 18 Feb. 2011: After some gentle nudging from Cosma, I ran a simulation that better handles the uncertainty in estimating the attachment model; the improvement was to bootstrap the measured attachment rates before fitting the model, and then use that larger set of estimates to generate the distribution of crossing dates. Below is the result. The difference in the envelope of projections is noticeable, with a much wider range of crossing times for 1000 citations (a few trajectories never cross 1000), but the overprinting is deceptive. The inset shows that the distribution is mainly just wider. Comfortably, the middle of the distribution is about where it was before, with the median prediction at 12 June 2012 and the mode at 21 April 2012. The variance, as expected, is much larger, with the 5-95% quantiles now ranging from 11 Jan. 2012 all the way to 29 Nov. 2013.
-----
[1] One reason to distrust raw citation counts is that a citation doesn't provide any context for how people cite the paper. Some contexts include "everyone else cites this paper and so are we", "this is background material actually relevant to our paper", "this paper is wrong, wrong, wrong", "studies exist", "this paper mentions, in a footnote, something we care about", "we've read this paper, thought about it deeply and are genuinely influenced by it", among many others.
[2] It's hard not to be pleased with this, although there is still work to be done in fixing the power-law literature: I still regularly see new articles on the arxiv or in print claiming to see power-law distributions in some empirical data and using linear-regression to support the claim, or using maximum likelihood to estimate the exponent but not calculating a p-value or doing the likelihood ratio test.
[3] I started tracking this data via Google Scholar about two years ago, so I'm missing the earlier part of the time series. Unfortunately, Google Scholar does not allow you to recover the lost data. In principle other citation services like ISI Web of Science would, since every publication they track includes its pub date. There are also other differences. Google Scholar tends to pick up peer-reviewed conference publications (important in computer science) while ISI Web of Science tracks only journals (and not even all of them, although it does get very many). Google Scholar also picks up other types of "publications" that ISI omits, including tech reports, pre-prints, etc., which some people think shouldn't count. And, sometimes Google Scholar takes citations away, perhaps because it can't find the citing document anymore or because the Google Scholar team has tweaked their algorithms. In the time series above, you can spot these dips, which would not appear in the corresponding ISI time series.
[4] "It's hard to make predictions, especially about the future," a saying attributed to many people, including Yogi Berra, Niels Bohr and Mark Twain.
[5] In fact, the precise form of the distribution is known. For Price's original model, which includes the more recent Barabasi-Albert model as a special case, the distribution follows the ratio of two Beta functions, and is known as the Yule-Simon distribution. This distribution has a power-law tail, and is named after Udny Yule and Herbert Simon, whose interest in preferential attachment predated Price's own interest, even though they weren't thinking about citations or networks. I believe Simon was the first to derive the limiting distribution exactly for the general model, in 1955. If you're interested in the history, math or data, I gave a lecture on this topic last semester in my topics course.
[6] S. Redner, "Citation Statistics from 110 years of Physical Review" Physics Today 58, 49 (2005).
[7] There are other ways we could arrive at a prediction, and better ways to handle the uncertainty in the modeling. For instance, none of the projections accounted for uncertainty in the parameters estimated from the attachment rate data, and including that uncertainty would lead to a distribution of predictions for a particular projection. Doing the same trick with the window length would probably lead to higher variance in the distribution of prediction dates, and might even shift the median date. (Computing the distribution of predicted dates over the different window lengths does account for some amount of the uncertainty, but not all of it.)
Another possibility is to be completely non-parametric about the attachment function's form, although additional questions would need to be answered about how to do a principled extrapolation of the attachment function into the unobserved citation count region.
Still another way would be to dispense with the proportional growth model completely and instead consider something like the daily attachment rate, projected forward in time. Surprisingly, this technique yields a similar prediction to the proportional growth model, probably because the non-linearity in the growth rate is relatively modest, so these models would only diverge on long time scales. This fact is a little bit like a model-comparison test, and suggests that at this point, it's unclear whether proportional growth is actually the better model of this paper's citation trajectory.
posted February 18, 2011 08:35 AM in Self Referential | permalink | Comments (5)
December 21, 2010
2010: a year in review
This is probably it for the year, so here's a look back at 2010, by the numbers.
Papers published (or accepted): 3
Other publications: 4 (two replies to comments, one invited editorial, one invited blog post)
Papers currently under review: 1
Manuscripts near completion: 4
Projects in-the-works: too many to count
Half-baked projects unlikely to be completed: already forgotten
Papers read: >433
Research talks given: 15
Public lectures: 1 (The Future of Terrorism)
Invited talks: 14
Visitors hosted: 8
Conferences, workshops organized: 0
Conferences, workshops, summer schools attended: 12
Number of those at which I delivered a research talk: 11
Number of times other people have written about my research: >6
Number of interviews about my research: 4
Number of times featured on slashdot: 1
Students advised: 3
Summer school faculty positions: 0
University courses taught: 1
Pages of lecture notes written for said course: >92
Number of problems assigned: 45
Pages of solutions written for said problems: 67
Pages of student work graded: 472
Number of class-related emails received: >402
Number of conversations with the faculty honor council liaison: 1
Number of days spent doing genuine research during the semester: 3 (sigh...)
Manuscripts reviewed for various journals, conferences: >29
Reviewing requests declined: >33
Book deals declined: 1
Program committees: 3
Grant proposals submitted: 6 (I'm told this is a lot, but I wouldn't know)
Grants awarded: 0
Grant proposals pending: 4
New grant proposals in the works: 4
Emails sent: >4727
Emails received (non-spam): >9234
Number of those about work-related topics: >7722
Number of computers purchased: 1
Blog entries written: 46 (up a little from last year)
Movies via Netflix: 15
Books purchased: 35
Songs added to iTunes: 123
Pictures posted on Flickr: 0
Major life / career changes: 1
Fun trips with friends / family: 7
Trips to Las Vegas, NV: 0
Trips to New York, NY: 0
States visited (in the US): 10
Foreign countries visited: 5 (France, Italy, Switzerland, Netherlands, Canada)
Other continents visited: 1
Airplane flights: 60
Total flight miles: 64000
Here's to a great year, and hoping that 2011 is just as good. (Although maybe a little less busy...)
posted December 21, 2010 08:06 AM in Self Referential | permalink | Comments (3)
December 14, 2010
Statistical Analysis of Terrorism
Yesterday, my work on global statistical patterns in terrorism [1] was featured in a long article in the magazine Miller-McCune called The Physics of Terrorism, written by Michael Haederle [2].
Much of the article focuses on the weird empirical fact that the frequency of severe terrorist attacks is well described by a power-law distribution [3,4], although it also discusses my work on robust patterns of behavior in terrorist groups, for instance, showing that they typically increase the frequency of their attacks as they get older (and bigger and more experienced), and moreover that they do it in a highly predictable way. There are several points I like most about Michael's article. First, he emphasizes that these patterns are not just nice statistical descriptions of things we already know, but rather they show that some things we thought were fundamentally different and unpredictable are actually related and that we can learn something about large but rare events by studying the more common smaller events. And second, he emphasizes the fact that these patterns can actually be used to make quantitative, model-based statistical forecasts about the future, something current methods in counter-terrorism struggle with.
Of course, there's a tremendous amount of hard-nosed scientific work that remains to be done to develop these empirical observations into practical tools, and I think it's important to recognize that they will not be a silver bullet for counter-terrorism, but they do show us that much more can be done here than has been traditionally believed and that there are potentially fundamental constraints on terrorism that could serve as leverage points if exploited appropriately. That is, so to speak, there's a forest out there that we've been missing by focusing only on the trees, and that thinking about forests as a whole can in fact help us understand some things about the behavior of trees. I don't think studying large-scale statistical patterns in terrorism or other kinds of human conflict takes away from the important work of studying individual conflicts, but I do think it adds quite a bit to our understanding overall, especially if we want to think about the long-term. How does that saying go again? Oh right, "those who do not learn from history are doomed to repeat it" (George Santayana, 1863-1952) [5].
The Miller-McCune article is fairly long, but here are a few good excerpts that capture the points pretty well:
Last summer, physicist Aaron Clauset was telling a group of undergraduates who were touring the Santa Fe Institute about the unexpected mathematical symmetries he had found while studying global terrorist attacks over the past four decades. Their professor made a comment that brought Clauset up short. "He was surprised that I could think about such a morbid topic in such a dry, scientific way," Clauset recalls. "And I hadn’t even thought about that. It was just … I think in some ways, in order to do this, you have to separate yourself from the emotional aspects of it."
But it is his terrorism research that seems to be getting Clauset the most attention these days. He is one of a handful of U.S. and European scientists searching for universal patterns hidden in human conflicts — patterns that might one day allow them to predict long-term threats. Rather than study historical grievances, violent ideologies and social networks the way most counterterrorism researchers do, Clauset and his colleagues disregard the unique traits of terrorist groups and focus entirely on outcomes — the violence they commit.
“When you start averaging over the differences, you see there are patterns in the way terrorists’ campaigns progress and the frequency and severity of the attacks,” he says. “This gives you hope that terrorism is understandable from a scientific perspective.” The research is no mere academic exercise. Clauset hopes, for example, that his work will enable predictions of when terrorists might get their hands on a nuclear, biological or chemical weapon — and when they might use it.
It is a bird’s-eye view, a strategic vision — a bit blurry in its details — rather than a tactical one. As legions of counterinsurgency analysts and operatives are trying, 24-style, to avert the next strike by al-Qaeda or the Taliban, Clauset’s method is unlikely to predict exactly where or when an attack might occur. Instead, he deals in probabilities that unfold over months, years and decades — probability calculations that nevertheless could help government agencies make crucial decisions about how to allocate resources to prevent big attacks or deal with their fallout.
-----
[1] Here are the relevant scientific papers:
On the Frequency of Severe Terrorist Attacks, by A. Clauset, M. Young and K. S. Gledistch. Journal of Conflict Resolution 51(1), 58 - 88 (2007).
Power-law distributions in empirical data, by A. Clauset, C. R. Shalizi and M. E. J. Newman. SIAM Review 51(4), 661-703 (2009).
A generalized aggregation-disintegration model for the frequency of severe terrorist attacks, by A. Clauset and F. W. Wiegel. Journal of Conflict Resolution 54(1), 179-197 (2010).
The Strategic Calculus of Terrorism: Substitution and Competition in the Israel-Palestine Conflict, by A. Clauset, L. Heger, M. Young and K. S. Gleditsch Cooperation & Conflict 45(1), 6-33 (2010).
The developmental dynamics of terrorist organizations, by A. Clauset and K. S. Gleditsch. arxiv:0906.3287 (2009).
A novel explanation of the power-law form of the frequency of severe terrorist events: Reply to Saperstein, by A. Clauset, M. Young and K.S. Gleditsch. Forthcoming in Peace Economics, Peace Science and Public Policy.
[2] It was also slashdotted.
[3] If you're unfamiliar with power-law distributions, here's a brief explanation of how they're weird, taken from my 2010 article in JCR:
What distinguishes a power-law distribution from the more familiar Normal distribution is its heavy tail. That is, in a power law, there is a non-trivial amount of weight far from the distribution's center. This feature, in turn, implies that events orders of magnitude larger (or smaller) than the mean are relatively common. The latter point is particularly true when compared to a Normal distribution, where there is essentially no weight far from the mean.
Although there are many distributions that exhibit heavy tails, the power law is special and exhibits a straight line with slope alpha on doubly-logarithmic axes. (Note that some data being straight on log-log axes is a necessary, but not a sufficient condition of being power-law distributed.)
Power-law distributed quantities are not uncommon, and many characterize the distribution of familiar quantities. For instance, consider the populations of the 600 largest cities in the United States (from the 2000 Census). Among these, the average population is only x-bar =165,719, and metropolises like New York City and Los Angles seem to be "outliers" relative to this size. One clue that city sizes are not well explained by a Normal distribution is that the sample standard deviation sigma = 410,730 is significantly larger than the sample mean. Indeed, if we modeled the data in this way, we would expect to see 1.8 times fewer cities at least as large as Albuquerque (population 448,607) than we actually do. Further, because it is more than a dozen standard deviations above the mean, we would never expect to see a city as large as New York City (population 8,008,278), and largest we expect would be Indianapolis (population 781,870).
As a more whimsical second example, consider a world where the heights of Americans were distributed as a power law, with approximately the same average as the true distribution (which is convincingly Normal when certain exogenous factors are controlled). In this case, we would expect nearly 60,000 individuals to be as tall as the tallest adult male on record, at 2.72 meters. Further, we would expect ridiculous facts such as 10,000 individuals being as tall as an adult male giraffe, one individual as tall as the Empire State Building (381 meters), and 180 million diminutive individuals standing a mere 17 cm tall. In fact, this same analogy was recently used to describe the counter-intuitive nature of the extreme inequality in the wealth distribution in the United States, whose upper tail is often said to follow a power law.
Although much more can be said about power laws, we hope that the curious reader takes away a few basic facts from this brief introduction. First, heavy-tailed distributions do not conform to our expectations of a linear, or normally distributed, world. As such, the average value of a power law is not representative of the entire distribution, and events orders of magnitude larger than the mean are, in fact, relatively common. Second, the scaling property of power laws implies that, at least statistically, there is no qualitative difference between small, medium and extremely large events, as they are all succinctly described by a very simple statistical relationship.
[4] In some circles, power-law distributions have a bad reputation, which is not entirely undeserved given the way some scientists have claimed to find them everywhere they look. In this case, though, the data really do seem to follow a power-law distribution, even when you do the statistics properly. That is, the power-law claim is not just a crude approximation, but a bona fide and precise hypothesis that passes a fairly harsh statistical test.
[5] Also quoted as "Those who cannot remember the past are condemned to repeat their mistakes".
posted December 14, 2010 10:39 AM in Scientifically Speaking | permalink | Comments (6)
August 16, 2010
Phase change
 Today I started work as an Assistant Professor of Computer Science at the University of Colorado at Boulder.
Today I started work as an Assistant Professor of Computer Science at the University of Colorado at Boulder.
My three and a half years as a postdoc at the Santa Fe Institute were intense and highly educational. As I've been saying recently when people asked me, I feel like I really found my own voice as a young scholar at SFI, developing my own perspective on the general areas I work in, my own research agenda for the foreseeable future, and a distinct approach to scientific problems. I've also written a few papers that, apparently, a lot of people really like.
As a professor now, I get to learn a lot of new stuff including how to teach, how to build and run a research group, and how to help run a department, among other things. I hope this next phase is as much or even more fun than the last one. I plan to continue to blog as regularly as I can, and probably about many of the same topics as before, along with new topics I become interested in as a result of hanging out more with computer scientists. Should be fun!
posted August 16, 2010 09:46 AM in Self Referential | permalink | Comments (0)
June 11, 2010
The Future of Terrorism
Attention conservation notice: This post mainly concerns an upcoming Public Lecture I'm giving in Santa Fe NM, as part of the Santa Fe Institute's annual lecture series.
Wednesday, June 16, 2010, 7:30 PM at the James A. Little Theater
Nearly 200 people died in the Oklahoma City bombing of 1995, over 200 died in the 2002 nightclub fire in Bali, and at least 2700 died in the 9/11 attacks on the World Trade Center Towers. Such devastating events captivate and terrify us mainly because they seem random and senseless. This kind of unfocused fear is precisely terrorism's purpose. But, like natural disasters, terrorism is not inexplicable: it follows patterns, it can be understood, and in some ways it can be forecasted. Clauset explores what a scientific approach can teach us about the future of modern terrorism by studying its patterns and trends over the past 50 years. He reveals surprising regularities that can help us understand the likelihood of future attacks, the differences between secular and religious terrorism, how terrorist groups live and die, and whether terrorism overall is getting worse.
Naturally, this will be my particular take on the topic, driven in part by my own research on patterns and trends in terrorism. There are many other perspectives, however. For instance, from the US Department of Homeland Security (from 2007), the US Department of Justice (from 2009) and the French Institute for International Relations (from 2006). Perhaps the main difference between these and mine is in my focus on taking a data- and model-driven approach to understanding the topic, and on emphasizing terrorism worldwide rather than individual conflicts or groups.
Update 13 July 2010: The video of my lecture is now online. The running time is about 80 minutes; the talk lasted about 55 and I spent the rest of the time taking questions from the audience.
posted June 11, 2010 08:49 PM in Terrorism | permalink | Comments (0)
April 29, 2010
What have I been doing these past 8 years?
The other day while contemplating this whole business of being a university professor, recruiting students, etc., it occurred to me that my current website doesn't have the usual blah-blah-blah boilerplate descriptions about the topics I work on and the questions I'm interested in. I'll probably write something eventually, but for now, I decided to take a data-driven approach to describing what I do: I took the text of almost all the papers I've written since 2003, threw them into a text file, munged things a little [1], and made a of the results.
Voila. Here's what I work on.

-----
[1] The munging is not strictly necessary, but wordle.net's implementation of the word cloud algorithm doesn't do "stemming", i.e., it doesn't see that words like "distribution" and "distributions" are really the same. So, some munging is necessary to combine words that are really the same.
posted April 29, 2010 06:34 AM in Self Referential | permalink | Comments (3)
March 29, 2010
The trouble with community detection
Attention conservation notice: this is a posting about a talk I'm giving tomorrow at Dalhousie University in Nova Scotia.
For most of this week, I'll be visiting the math department of Dalhousie University in Halifax Nova Scotia, as a speaker in the Modelling and Mining of Network Information Spaces seminar series and a guest of Jeannette Janssen.
For my part, I'm giving a talk (see below) on the results of my summer student Ben Good's project on the difficulties of identifying dense "communities" (or "modules", or "compartments") in networks using topological information alone. I'm pleased to say that this paper was recently accepted at Physical Review E. [1]
The problem of detecting communities in networks has received an enormous amount of attention (more than it deserves, in my opinion), and there are now literally dozens of reasonable-sounding ways to find the "clusters" in networks. To give you a sense of just how much attention, the first few papers in the field have received hundreds of citations and a few have even received thousands. And yet, I'm increasingly skeptical that all this effort has produced much of lasting value. On the up side, it's produced lots of clever methodological tricks and insights, and certainly I've enjoyed chewing on these problems myself [2]. But, I'm increasingly pessimistic about the goal of automatically extracting meaningful "clusters" from interaction data alone. In short, I don't believe there is a universally useful definition of a network cluster and I'm skeptical that any of the community detection methods currently available actually produce results that can be trusted.
Current methods do okay on trivial test cases of various kinds, but they all have methodological problems (some of them quite severe) that make it difficult to unambiguously interpret the scientific significance of their output. And, every method makes assumptions that are almost surely highly unrealistic for almost any system you might care to think about. On the other hand, some standard data analysis methods have similar problems (e.g., hierarchical clustering algorithms for spatial data) but still manage to be useful. I think this is partly because we understand pretty well how these methods fail, and thus how their output should be interpreted and under what conditions they can be expected to perform unambiguously. I don't think we're there yet with network clustering methods, but perhaps one day we'll get there.
If you're in the Halifax area and are interested in the talk, here are the details:
Date: Tuesday March 30, 2010 at 2:30 p.m.
Location: Jacob Slonim Conference Room (430), 6050 University Ave., Halifax
Coffee and cookies will be provided, courtesy of Faculty of Computer Science.
The trouble with community detection
Although widely used in practice, the performance of the popular network clustering technique called "modularity maximization" is not well understood when applied to networks with unknown modular structure. In this talk, I'll show that precisely in the case we want it to perform the best--that is, on modular networks--the modularity function Q exhibits extreme degeneracies, in which the global maximum is hidden among an exponential number of high-modularity solutions. Further, these degenerate solutions can be structurally very dissimilar, suggesting that any particular high-modularity partition, or statistical summary of its structure, should not be taken as representative of the other degenerate solutions. These results partly explain why so many heuristics do well at finding high-modularity partitions and why different heuristics can disagree on the modular composition the same network. I'll conclude with some forward-looking thoughts about the general problem of identifying network modules from connectivity data alone, and the likelihood of circumventing this degeneracy problem.
Update 31 March 2010: For those of you interested in reproducing our results or applying our methods to your own networks, Ben has placed implementations online here for his simulated annealing code for sampling the local optima of the modularity function and his code for taking those sampled optima and reconstructing the 3D visualization of the modularity landscape.
Update 15 April 2010: Updated the journal ref.
-----
[1] B. H. Good, Y.-A. de Montjoye and A. Clauset. " The performance of modularity maximization in practical contexts." Physical Review E 81, 046106 (2010).
[2] My most cited paper, by far, is my first paper on detecting communities by maximizing modularity using a greedy agglomerative algorithm.
posted March 29, 2010 08:24 AM in Self Referential | permalink | Comments (4)
January 12, 2010
The future of terrorism
Here's one more thing. SFI invited me to give a public lecture as part of their 2010 lecture series. These talks are open to, and intended for, the public. They're done once a month, in Santa Fe NM over most of the year. This year, the schedule is pretty impressive. For instance, on March 16, Daniel Dennett will be giving a talk about the evolution of religion.
My own lecture, which I hope will be good, will be on June 16th:
One hundred sixty-eight people died in the Oklahoma City bombing of 1995, 202 people died in the 2002 nightclub fire in Bali, and at least 2749 people died in the 9/11 attacks on the World Trade Center Towers. Such devastating events captivate and terrify us mainly because they seem random and senseless. This kind of unfocused fear is precisely terrorism's purpose. But, like natural disasters, terrorism is not inexplicable: it follows patterns, it can be understood, and in some ways it can be forecasted. Clauset explores what a scientific approach can teach us about the future of modern terrorism by studying its patterns and trends over the past 50 years. He reveals surprising regularities that can help us understand the likelihood of future attacks, the differences between secular and religious terrorism, how terrorist groups live and die, and whether terrorism overall is getting worse.
Also, if you're interested in my work on terrorism, there's now a video online of a talk I gave on their group dynamics last summer in Zurich.
posted January 12, 2010 10:53 AM in Self Referential | permalink | Comments (2)
December 26, 2009
2009: a year in review
This is it for the year, so here's a look back at 2009, by the numbers.
Papers published (or accepted) on which I was first author or a major contributor: 8
Papers currently under review: 1
Manuscripts near completion: 2
Projects in-the-works: too many to count
Half-baked projects unlikely to be completed: already forgotten
Papers read: >360
Research talks given: 13
Invited talks: 10
Conferences / workshops / summer schools attended: 6
Number of those at which I delivered a research talk: 3
Number of times other people have written about my research: >6
Number of computers purchased: 1
Students advised: 2
Summer schools taught at: 1
Manuscripts reviewed for various journals / conferences: >30
Reviewing requests declined: >30
Program committees: 5
Conferences / workshops organized: 1
Visitors hosted: 18
Grants submitted: 3
Grants awarded: 0
Grants pending: 1
Emails sent: >3483
Emails received (non-spam): >8660
Number of those about work-related topics: >5525
Blog entries written: 35 (this number is about as depressing as last year)
Movies via Netflix: 27
Books purchased online: 33
Songs added to iTunes: 369
Pictures posted on Flickr: 259
Cycling centuries completed: 1
Cars purchased: 1
Major life / career decisions: 2
Faculty jobs accepted: 1
Rings purchased: 3
Weddings: 1
Fun trips with friends / family: >8
Trips to Las Vegas, NV: 2
Trips to New York, NY: 0
States visited (in the US): 8
Foreign countries visited: 3 (China, Switzerland, Korea)
Other continents visited: 2
Airplane flights: 51
Here's to a great year, and hoping that 2010 is just as good!
posted December 26, 2009 09:19 AM in Self Referential | permalink | Comments (4)
November 29, 2009
If you're in Korea this week...
I'm giving three talks, while I'm here visiting Petter Holme. The last time I was in Korea was back in 2007, to visit Hawoong Jeong. I'll have less time for sight seeing, but I'm happy to say that I'll have more than 2 hours between walking off the plane and giving my talk this time (which was entirely my fault last time).
The first is at Sungkyunkwan University (Suwon campus), Monday Nov. 30th (at 16h00; email Petter for details). The second is at Seoul National University on Wednesday Dec. 2nd (also at 16h00, directly after Petter's talk; contact our host Byungnam Kahng for details), and the third is at KAIST on Thursday Dec. 3rd (not sure when; contact our host Hawoong Jeong for details). I'll be talking about the dynamics of terrorist groups and how the frequency and severity of their attacks evolves over their lifetime.
posted November 29, 2009 05:08 PM in Self Referential | permalink | Comments (0)
October 31, 2009
Happy halloween!
Last year I was in New York City for Halloween. But, this year, I was at home, which meant it was time to carve another pumpkin. This time, I made a starry night:

(This was my first time using power tools to carve a pumpkin, and I have to say, they make it a lot easier and a lot more fun!)
posted October 31, 2009 10:27 PM in Self Referential | permalink | Comments (3)
May 22, 2009
Goodbye postdoc
I'm happy to announce that after a great deal of thought and many conversations with my fiance Lisa [1], I've accepted a tenure-track faculty position in the Computer Science Department at the University of Colorado, Boulder. This position is part of the Colorado Initiative in Molecular Biotechnology, which means I'll be hanging out a lot more with molecular biologists and other people who love to study things that go squish. The CIMB is a great initiative that I think will suit me well: one of it's stated purposes is to bring together scientists from a wide variety of disciplines, including computer science, applied math, physics, chemistry, biology and ecology, and I like the inclusion of technology in its focus. Plus, Boulder seems like a great place to live.
The appointment starts in the Fall of 2010, which gives me another year to finish out my postdoc at the Santa Fe Institute, and, more importantly, to finish up a lot of the projects that I've started here on topics like macroevolution and the mathematics of terrorism. So, come Summer 2010, it'll be goodbye postdoc, and hello responsibility! Wish me luck!
-----
[1] Oh yeah. I'm getting married, too!
posted May 22, 2009 03:33 PM in Self Referential | permalink | Comments (4)
December 31, 2008
2008: a year in review
Here's a look back at 2008, by the numbers.
Papers published (or accepted) on which I was first author or a major contributor: 6
Papers currently under review: 1
Manuscripts near completion: 2
Projects in-the-works: 10
Half-baked projects unlikely to be completed: 3
Papers read: >240
Research talks given: 10
Invited talks: 6
Conferences / workshops / summer schools attended: 6
Number of those at which I delivered a research talk: 5
Number of times other people have written about my research: 11
Number of times featured on slashdot.org: 1 (and a longtime dream was fulfilled!)
Number of computers purchased: 1
Students advised: 2
Summer schools taught at: 2
Manuscripts reviewed for various journals / conferences: >17
Program committees: 2
Conferences / workshops organized: 2
Visitors hosted: 22
Grants awarded: 1
Grants pending: 1
Emails sent: >3572
Emails received (non-spam): >6831
Number of those about work-related topics: >5197
Blog entries written: 36 (this number is much more depressing than last year)
Movies via Netflix: 22
Books purchased online: 20
Pictures posted on Flickr: 406
TVs replaced: 1
Elections voted in: 2
Races (running or cycling) completed: 3
Major life / career decisions: 1
Fun trips with friends / family: >12
Trips to Las Vegas, NV: 1
Trips to New York, NY: 1
States visited (in the US): 9
Foreign countries visited: 4 (China, Switzerland, France, Peru)
Continents visited: 3 (including my first trip to South America)
Airplane flights: 53
And, I published papers in both Nature and Science.
Here's to a great year, and hoping that 2009 is just as good!
posted December 31, 2008 11:21 AM in Self Referential | permalink | Comments (3)
November 16, 2008
This might be it for the year
I'm sad to say that this might be about it for the rest of the year, in terms of real blog posts. Starting next weekend, I'll be in Europe for a week and a half. My first stop is Zurich Switzerland where I'll be giving a talk at ETH Zurich's "Modeling Complex Socio-Economic Systems and Crises" seminar about my work on the statistical patterns in terrorism. And, since it's a long way to go for a short trip, Lisa and I are taking the train to Paris France right after to celebrate Thanksgiving in the land of the baguette. Almost immediately after I get back from Europe, I'm running a workshop at SFI called Statistical Inference for Complex Networks, which should be very stimulating. Then, I'll have a few days to wrap loose ends before I fly to Peru for two weeks to, among other things, hike the Inca Trail and see Machu Picchu. When I get back, 2008 will be all but over, and it'll be time to do my year-in-review post.
Update 5 January 2009: If you're interested, I've posted many of my pictures from Peru and the Inca Trail on my Flickr photostream.
posted November 16, 2008 09:54 PM in Self Referential | permalink | Comments (1)
October 28, 2008
NYC
This week, and most of next, I'm in New York City. It's been over a year since I was last here, so there's potentially a lot to catch up on in a short period of time. Mainly, I'll be giving a talk at Yahoo! Research, chatting with colleagues there about network analysis, and then attending and presenting at the DIMACS / DyDAn workshop on Network Models of Biological and Social Contagion. I'll also be in NYC on Election Day, which I think will be very exciting.
posted October 28, 2008 12:07 PM in Self Referential | permalink | Comments (0)
October 04, 2008
Hanging out with rock scientists
Later today I fly to Houston [1] to participate in the Geological Society of America (GSA)'s 2008 annual meeting [2]. The conference itself is huge, with attendance easily in the thousands. Over the past few weeks, it's amused me to no end all the advertisements for the latest spectrographic rock analyzer that I've gotten in the mail. It's almost like being a real scientist, or something.
Anyway, I'm going to present my work on models of species body size evolution at the "Paleontology I - Macroevolution, Diversity, and Biogeography" session. I guess rocks and fossils are close enough that it fits. The talk will be short, but I'm going to try to cover not just my work that appeared in Science with Doug Erwin, but also my more recent work on birds and the diversification of mammals 70 million years ago.
I'm very much looking forward to the conference: it'll be an opportunity to interact with scientists who are very focused on understanding the incredibly complex history of life on this planet, and to learn about new and interesting mysteries (to me, at least). With any luck, I'll come back with new colleagues I can talk to about things like the origin of diversity, the importance of extinction events to fundamental innovation (a topic that relates to technological innovations, too), etc. With any luck, I'll also come back with some new ideas to work on.
-----
[1] The conference center is in downtown Houston, which is where a lot of damage from Hurricane Ike happened, so it'll also be interesting to see how well Houston has recovered. Earlier this summer, I spent a week in New Orleans, and it was eye opening to see both how much and how little recovery has been done there, even two years after Hurricane Katrina.
[2] To get a discount on the conference fees, I signed up to be an official member of the GSA. Thankfully, there was not pre-requisite that I own a rock hammer, or have a rock collection at home! At various points now, I've been a member of professional organizations in physics, computer science, biology, political science, and geology... yow.
posted October 4, 2008 09:59 AM in Self Referential | permalink | Comments (0)
July 21, 2008
Evolution and Distribution of Species Body Size
One of the most conspicuous and most important characteristics of any organism is its size [1]: the size basically determines the type of physics it faces, i.e., what kind of world it has to live in. For instance, bacteria live in a very different world from insects, and insects live in a very different world from most mammals. In a bacterium's world, nanometers and micrometers are typical scales and some quantum effects are significant enough to drive some behaviors, but larger-scale effects like surface tension and gravity have a much more indirect effect. For most insects, typical scales are millimeter and centimeters, where quantum effects are negligible, but the surface tension of water matters tremendously. Similarly, for most mammals [2], a typical scale is more like a meter, and surface tension isn't as important as gravity and supporting your own body weight.
And yet despite these vast differences in the basic physical world that different types of species encounter, the distribution of body sizes within a taxonomic group, that is, the relative number of small, medium and large species, seems basically the same regardless of whether we're talking about insects, fish, birds or mammals: a few species in a given group are very small (about 2 grams for mammals), most species are slightly larger (between 20 and 80 grams for mammals), but some species are much (much!) larger (like elephants, which weigh over 1,000,000 times more than the smallest mammal). The ubiquity of this distribution has intrigued biologists since they first began to assemble large data sets in the second-half of the 20th century.
Many ideas have been suggested about what might cause this particular, highly asymmetric distribution, and they basically group into two kinds of theories: optimal body-size and diffusion. My interest in answering this question began last summer, partly as a result of some conversations with Alison Boyer in another context. Happily, the results of this project were published in Science last week [3] and basically show that the diffusion explanation is, when fossil data is taken in account, really quite good. (I won't go into the optimal body-size theories here; suffice to say that it's not as popular a theory as the diffusion explanation.) At its most basic, the paper shows that, while there are many factors that influence whether a species gets bigger or smaller as it evolves over long periods of time, their combined influence can be modeled as a simple random walk [4]. For mammals, the diffusion process is, surprisingly I think, not completely agnostic about the current size of a species. That is, although a species experiences many different pressures to get bigger or smaller, the combined pressure typically favors getting a little bigger (but not always). The result of this slight bias toward larger sizes is that descendent species are, on average, 4% larger than their ancestors.
But, the diffusion itself is not completely free [5], and its limitations turn out to be what cause the relative frequencies of large and small species to be so asymmetric. On the low end of the scale, there are unique problems that small species face that make it hard to be small. For instance, in 1948, O. P. Pearson published a one-page paper in Science reporting work where he, basically, stuck a bunch of small mammals in an incubator and measured their oxygen (O2) consumption. What he discovered is that O2 consumption (a proxy for metabolic rate) goes through the roof near 2 grams, suggesting that (adult) mammals smaller than this size might not be able to find enough high-energy food to survive, and that, effectively, 2 grams is the lower limit on mammalian size [6]. On the upper end, there is an increasingly dire long-term risk of become extinct the bigger a species is. Empirical evidence, both from modern species experiencing stress (mainly from human-related sources) as well as fossil data, suggests that extinction seems to kill off larger species more quickly than smaller species, with the net result being that it's hard to be big, too.
Together, this hard lower-limit and soft upper-limit on the diffusion of species sizes shape distribution of species in an asymmetric way and create the distribution of species sizes we see today [7]. To test this hypothesis in a strong way, we first estimated the details of the diffusion model (such as the location of the lower limit and the strength of the diffusion process) from fossil data on about 1100 extinct mammals from North America that ranged from 100 million years ago to about 50,000 years ago. We then simulated about 60 million years of mammalian evolution (since dinosaurs died out), and discovered that the model produced almost exactly the size distribution of currently living mammals. Also, when we removed any piece of the model, the agreement with the data became significantly worse, suggesting that we really do need all three pieces: the lower limit, the size-dependent extinction risk, and the diffusion process. The only thing that wasn't necessary was, surprisingly, the bias toward slightly larger species in the diffusion itself [8], which I think most people thought was necessary to produce really big species like elephants.
Although this paper answers several questions about why the distribution of species body size is the way it is, there are several questions left unanswered, which I might try to work on a little in the future. In general, one exciting thing is that this model offers some possibilities for connecting macroevolutionary patterns, such as the distribution of species body sizes over evolutionary time, with ecological processes, such as the ones that make larger species become extinct more quickly than small species, in a relatively compact way. That gives me some comfort, since I'm sympathetic to the idea that there are reasons we see such distinct patterns in the aggregate behavior of biology, and that it's possible to understand something about them without having to understand the specific details of every species and every environment.
-----
[1] An organism's size is closely related, but not exactly the same as its mass. For mammals, their density is very close to that of water, but plants and insects, for instance, can be less or more dense than water, depending on the extent of specialized structures.
[2] The typical mammal species weights about 40 grams, which is the size of the Pacific rat. The smallest known mammal species are the Etruscan shrew and the bumblebee bat, both of whom weight about 2 grams. Surprisingly, there are several insect species that are larger, such as the titan beetle which is known to weigh roughly 35 grams as an adult. Amazingly, there are some other species that are larger still. Some evidence suggests that it is the oxygen concentration in the atmosphere that mainly limits the maximum size of insects. So, about 300 million years ago, when the atmospheric oxygen concentrations were much higher, it should be no surprise that the largest insects were also much larger.
[3] A. Clauset and D. H. Erwin, "The evolution and distribution of species body size." Science 321, 399 - 401 (2008).
[4] Actually, in the case of body size variation, the random walk is multiplicative meaning that changes to species size are more like the way your bank balance changes, in which size increases or decreases by some percentage, and less like the way a drunkard wanders, in which size changes by increasing or decreasing by roughly constant amounts (e.g., the length of the drunkard's stride).
[5] If it were a completely free process, with no limits on the upper or lower ends, then the distribution would be a lot more symmetric than it is, with just as many tiny species as enormous species. For instance, with mammals, an elephant weights about 10 million grams, and there are a couple of species in this range of size. A completely free process would thus also generate a species that weighed about 0.000001 grams. So, the fact that the real distribution is asymmetric implies that some constraints much exist.
[6] The point about adult size is actually an important one, because all mammals (indeed, all species) begin life much smaller. My understanding is that we don't really understand very well the differences between adult and juvenile metabolism, how juveniles get away with having a much higher metabolism than their adult counterparts, or what really changes metabolically as a juvenile becomes an adult. If we did, then I suspect we would have a better theoretical explanation for why adult metabolic rate seems to diverge at the lower end of the size spectrum.
[7] Actually, we see fewer large species today than we might have 10,000 - 50,000 years ago, because an increasing number of them have died out. The most recent population collapses are certainly due to human activities such as hunting, habitat destruction, pollution, etc., but even 10,000 years ago, there's some evidence that the disappearnace of the largest species was due to human activities. To control for this anthropic influence, we actually used data on mammal species from about 50,000 years ago as our proxy for the "natural" state.
[8] This bias is what's more popularly known as Cope's rule, the modern reformulation of Edward Drinker Cope's suggesting that species tend to get bigger over evolutionary time.
posted July 21, 2008 03:01 PM in Evolution | permalink | Comments (0)
June 23, 2008
Entering orbit around the Googleplex
Attention conservation notice: this is a posting about a workshop at Google's Mountain View complex.
I'll be giving a talk (1:30pm, Building 42, 2nd Floor; not sure if it's open to the public) about complex models of large-scale structure in networks at Google's Mountain View complex tomorrow, as part of a joint SFI workshop entitled "Selection Tinkering and Emergence in Complex Networks." The workshop is part of the Paramaribo Tech Talk series at Google; here's a brief explanation of the event:
This meeting will search for general principles of organization and evolution of natural and artificial systems changing through local rules based on reuse of previously existing substructures. Such a process of "tinkering" makes a big difference (at least in principle) when comparing biological structures and man-made artifacts. As pointed out by the French biologist François Jacob, the engineer is able to foresee the future use of the artifact (i.e. it acts as a designer) whereas evolution does not. The first can ignore previous designs, whereas the second is based on changes taking place by using available structures.
In spite of its apparent drawbacks, tinkering has been able to generate most complex structures observable in the real world (including some in the technological world). Very often, the resulting structures share common principles of organization, suggesting that convergent evolution towards a limited number of basic plans is inevitable. How innovations emerge through evolution is one of the key problems in complexity, and this meeting will focus towards understanding these problems, using several scales of analysis - from cellular networks and tissues to ecosystems - and using network approaches as a quantitative characterization of such complexity.
My contribution, I believe, is to talk about networks and how to extract meaningful information about their large-scale structure.
Update 28 June 2008: The visit to Google went quite well, I think. The Tech Talk was in one of the main buildings, and what seemed like a relatively central place. Throughout the day, Googlers passed by on their way to other places in the complex. During my talk, I noticed a few new faces in the audience, which I can only assume were locals.
What's fascinating about Google is, really its size. My understanding is that the core business -- the one that brings in the majority of the money -- is the AdSense division, which sells keywords to advertisers and places ads on various other sites. The AdSense group itself doesn't require much to run, so there's a tremendous surplus of cash, which Google has apparently been using to grow like crazy and to invest in interesting (but mostly not profitable) projects related to organizing information. In some sense, this makes Google a lot like the old Bell Labs, where massive amounts of extra money were devoted to risky projects, many of which didn't produce anything useful until years or decades later. On the other hand, there's a lot to be said for having a good reputation, and the kind of good PR that Google gets from free but useful products like GoogleEarth, etc. is the kind that you simply can't buy any other way.
Another thing that struck me about the Googleplex was the age demographic. One of my friends from grad school who works there now said that a quarter of everyone he meets has worked there for less time than he has. That's not because there's a high turnover rate, but because Google's just been hiring like crazy. And they've been hiring young people. The vast majority of people I saw were under 40 or so, and a big portion of them were under 30.
So, it's a strange place really -- not like most companies I've interacted with --lots of fringe benefits (free food everywhere, free services like haircuts and shuttles, 20% time to work on your own crazy projects, etc.), lots of freedom, lots of young people, etc. In some sense, the internal corporate philosophy seems to be one of bringing together lots of smart people and giving them the tools, impetus and freedom to do brilliant things. So, it seems like a great place to work, right now. If the cash surplus situation were to change dramatically for some reason (government anti-trust activity a la Microsoft, strong competition from Yahoo! or MSN, a collapse of Internet adversing, etc.), then I'm sure things would change, much as they did for Bell Labs in the 1990s when it was spun out from AT&T.
For researchers, Google seems like a pretty good place to be. The three Googler colleagues of mine that I chatted with while I was there all have PhDs and all seemed to be really happy with their jobs. Of course, none had been there for that long, but one of them, who works on understanding the internal organizational dynamics of the company, mentioned that the retirement / quitting rate is very very low. So, like I said, it seems like a really good place to work, for now.
posted June 23, 2008 08:40 AM in Self Referential | permalink | Comments (1)
May 23, 2008
Shaping up to be a good year
Yesterday I heard the good news that my first paper (with Doug Erwin) on biology and evolution was accepted at Science. Unlike my experience with publishing in Nature, the review process for this paper was fast and relatively painless. I think this was partly because the paper's topic, on the evolution of species body masses, is a relatively conventional one in paleobiology / evolutionary biology / ecology. In fact, people have been thinking about this topic for more than 100 years, going all the way back to E. D. Cope in 1887 who suggested that mammal species had an inherent tendency to become larger over evolutionary timescales (millions of years). This idea went through several reformulations as our understanding of evolution matured over the 20th century. From a modern perspective, we now know from fossil data that changes to how big a species is are not deterministic in the sense that they always get bigger (as Cope thought), but rather changes are stochastic, with both decreases and increases happening with great frequency. The tendency, however, for many kinds of species (including mammals and brachiopods) is that the increases slightly outnumber the decreases (a pattern called Cope's Rule), perhaps because of competitive or robustness advantages from increased size.
Anyway, there's a lot more to say on this topic, but I'll wait until the paper comes out to say it. In general, it's been a lot of fun learning about evolution and ecology, and I hope to do some more work in this area in the future.
posted May 23, 2008 08:20 AM in Self Referential | permalink | Comments (2)
February 22, 2008
Returning to the alma mater
Next week I'll be visiting my old stomping ground Haverford College, as well as nearby Swarthmore and Bryn Mawr Colleges. A couple of years ago I went to my 5 year reunion there, but this will be my first time back in an "official" academic capacity. It promises to be an exhausting experience (largely because of how many things I've packed into the 4 day visit), but also a slightly surreal one as I'll be on the other side of the teacher-student divide at a place that was really important in the grand scheme of my intellectual career.
To start, I'll be giving a research talk at Swarthmore on Monday (4:00pm in the Science Center, if any of you are local) on some of my recent work on modeling evolutionary trends in species body size. I'll also be chatting with students over lunch about graduate school and jobs in the industry. The next day, I'm giving a guest lecture in a computational physics course at Haverford (I'll be talking about statistical method for network analysis, including an introduction to MCMC in the context of fitting models to data). Lunch that day will be a chat with students from the CS department. Wednesday, I'm paying an early-morning visit to the Emergence discussion group at Bryn Mawr, followed by lunch with physics students. To wrap things up, I'll be briefly returning to Bryn Mawr on Thursday to chat with CS students, before heading back to New Mexico. Sprinkled throughout these events will be meetings with faculty, some I knew from my time in college like Jerry Gollub and Suzanne Amador, and some who are new to me like Steve Wang.
One of my friends here at SFI mentioned that my schedule for next week sure sounds a lot like I'm interviewing for a position at these schools. Fortunately, it's not. Otherwise, I'd be a little more stressed about it... On the other hand, I remember the last year or so at Haverford and the first few years of graduate school thinking that it would be a great job to be a professor at a small liberal arts college (SLAC) like Haverford, where the students are smart and hard working, and there's both space and support to do interesting research. I still mostly agree, although I've also become completely enamored with doing cool research, and you certainly don't have as much time at a SLAC to do research as you do at a bigger, more research-focused university. At this point, though, it's not clear to me how I'll feel when the time finally does come to get one of those tenure-track jobs.
Update 3 March 2008: I've now posted a pdf scan of my lecture notes. Obviously, these omit the narrative and the bits that I added on the fly to make the lecture more coherent. Also, in my lecture, I didn't have time to explain the last several slides of results from using the HRG model in an MCMC context. If you find any mistakes in them, please do let me know.
posted February 22, 2008 09:02 AM in Self Referential | permalink | Comments (3)
December 28, 2007
2007: a year in review
As the last days of 2007 dwindle, here's a look back on my year, by the numbers.
Papers published on which I was first author or a major contributor: 3
Papers currently under review: 4
Manuscripts near completion: 1
Software packages released: 2
Half-baked projects unlikely to be completed: 5
Projects in-the-works: 3
Manuscripts reviewed for various journals / conferences: >10
Papers read: >120
Research talks given: 15
Invited talks: 7
Conferences / workshops / summer schools attended: 15
Number of those at which I delivered a research talk: 11
Students advised: 2
Conferences / workshops organized: 1
Grants awarded: 1
Grants pending: 2
Emails sent: >2588
Emails received (non-spam): >6104 (these numbers are still depressingly high)
Number of those about work-related topics: >4293
Plane flights: 44 (woe is my carbon footprint)
Laptops stolen: 2 (one was my replacement; stolen off the back of a FedEx truck)
Blog entries written: 80 (this number is only marginally less depressingly than last year)
Movies via Netflix: 46
Pictures posted on Flickr: 169
Major life / career decisions: 0
Fun trips with friends / family: >15
Foreign countries visited: 2 (Italy and South Korea)
Weddings attended: 1
Yards landscaped: 2
And, I met Oprah.
posted December 28, 2007 10:33 AM in Self Referential | permalink | Comments (0)
December 19, 2007
Just in time for the holidays
There's excellent coverage elsewhere of the recent trashing of science funding by Congress and the Whitehouse, for instance, Cosmic Variance, Science Magazine (with gruesome details about who didn't get what), and Computer Research Policy Blog (with details on all the devious tricks pulled to make the funding changes look less terrible than they actually are).
The past few years have seen support for basic research decline quite a bit at the federal level (for instance, the DoD basically eliminated all of its basic research funding, which forced many of its previous researchers to go instead to the already overburdened NSF for funds). The funding decrease this year would have only produced a lot of grumbling and complaining, and probably even a lot of upset letters had it not been for the promises by Congress and the Whitehouse for funding increases this year (via the America COMPETES initiative (whitehouse.gov link).
In other, more happy news, I just had my first paper accepted at Nature. The review process was considerably more painful than I expected. The final product is certainly improved over the initial one, on account of changes we made to address some of the questions by the reviewers (along with changes based on feedback from many talks I've given on the topic over the past year). It's comforting to know that good, interdisciplinary work can actually get published in a vanity journal like Nature. That being said, I really prefer to write papers in which I can actually discuss the technical details in the main body of the paper, rather than hiding them all in the appendices that no one actually reads. I also like writing papers longer than 15 paragraphs.
With that, happy holidays to you all. I head east in the morning for the usual family festivities, which will induce yet another hiatus from blogging for me. I'll return to beautiful New Mexico just in time to do my usual year-end blog wrap up here.
posted December 19, 2007 09:05 PM in Rant | permalink | Comments (3)
November 01, 2007
What did you do this halloween?
Here's what I did:

posted November 1, 2007 09:57 AM in Self Referential | permalink | Comments (0)
June 08, 2007
Power laws and all that jazz
With apologies to Tolkien:
Three Power Laws for the Physicists, mathematics in thrall,
Four for the biologists, species and all,
Eighteen behavioral, our will carved in stone,
One for the Dark Lord on his dark throne.
In the Land of Science where Power Laws lie,
One Paper to rule them all, One Paper to find them,
One Paper to bring them all and in their moments bind them,
In the Land of Science, where Power Laws lie.
From an interest that grew directly out of my work chracterizing the frequency of severe terrorist attacks, I'm happy to say that the review article I've been working on with Cosma Shalizi and Mark Newman -- on accurately characterizing power-law distributions in empirical data -- is finally finished. The paper covers all aspects of the process, from fitting the distribution to testing the hypothesis that the data is distributed according to a power law, and to make it easy for folks in the community to use the methods we recommend, we've also made our code available.
So, rejoice, rejoice all ye people of Science! Go forth, fit and validate your power laws!
For those still reading, I have a few thoughts about this paper now that it's been released into the wild. First, I naturally hope that people read the paper and find it interesting and useful. I also hope that we as a community start asking ourselves what exactly we mean when we say that such-and-such a quantity is "power-law distributed," and whether our meaning would be better served at times by using less precise terms such as "heavy-tailed" or simply "heterogeneous." For instance, we might simply mean that visually it looks roughly straight on a log-log plot. To which I might reply (a) power-law distributions are not the only thing that can do this, (b) we haven't said what we mean by roughly straight, and (c) we haven't been clear about why we might prefer a priori such a form over alternatives.
The paper goes into the first two points in some detail, so I'll put those aside. The latter point, though, seems like one that's gone un-addressed in the literature for some time now. In some cases, there are probably legitimate reasons to prefer an explanation that assumes large events (and especially those larger than we've observed so far) are distributed according to a power law -- for example, cases where we have some convincing theoretical explanations that match the microscopic details of the system, are reasonably well motivated, and whose predictions have held up under some additional tests. But I don't think most places where power-law distributions have been "observed" have this degree of support for the power-law hypothesis. (In fact, most simply fit a power-law model and assume that it's correct!) We also rarely ask why a system necessarily needs to exhibit a power-law distribution in the first place. That is, would the system behave fundamentally differently, perhaps from a functional perspective, if it instead exhibited a log-normal distribution in the upper tail?
Update 15 June: Cosma also blogs about the paper, making many excellent points about the methods we describe for dealing with data, as well as making several very constructive points about the general affair of power-law research. Well worth the time to read.
posted June 8, 2007 10:00 AM in Complex Systems | permalink | Comments (3)
April 26, 2007
The month of May
The month of May is a busy one for me. For some reason, it's when most of the big networks-related workshops and conferences happen, so I end up spending most of it on the road. This year, I'm attending four conferences, in four states, two of which are on opposite coasts. The agenda:
Algorithms, Inference, and Statistical Physics (AISP), run by CNLS of Los Alamos National Lab and hosted in Santa Fe. This workshop runs May 1 - 4, and I'm giving a short talk on power-law distribution in empirical data.
Then, it'll be over to the Institute for Pure and Applied Mathematics (IPAM) at UCLA for their workshop on Random and Dynamic Graphs and Networks.
I get a short reprieve, and then its off to New York City for the over-named International Conference on Network Science (NetSci), which is trying to position itself as the main event in the field of complex networks each year. Given the number of physicists that present work at the APS March Meeting, that's going to be quite a task. But, at least NetSci attracts some folks outside of physics, such as a few folks in sociology, ecology and microbiology.
And then finally, it's over to Utah for the SIAM's conference on Applications of Dynamical Systems (DS07). There I'll be giving a talk on the hierarchical organization of networks at a mini-symposium on complex networks organized by Mason Porter and Peter Mucha.
Then, I'll return to Santa Fe exhausted, but enlightened from interacting with my esteemed colleagues, and seeing a few friends that live in faraway places. Ah, conference season. How I love thee. How I loathe thee.
posted April 26, 2007 06:49 PM in Self Referential | permalink | Comments (0)
April 15, 2007
A rose is a rose
Warning: Because I'm still recovering from my catastrophic loss last Monday, blogging will be light or ridiculous for a little while longer. So, without further ado...
A few weeks ago, I inadvertently initiated a competition in the comment thread of Scott Aaronson's blog on how to identify physicists. It all started with Scott claiming that he was not a mathematician (as New Scientist claimed he was in an article about D-wave's press releases about quantum computers). As various peoples weighed in on Scott's mathematicianness, finally Dave Bacon proposed a sure fire way to settle the question:
Place yourself and a large potted plant in a huge room together. If you get tangled up in the plant, you are a mathematician. I draw this test from careful observation of the MSRI in Berkeley.
I then wondered aloud how to identify physicists, and I was returned a laundry list of characteristic behaviors:
- Hearing the word “engineering” causes a skin rash. [John Sidles]
- Writes “a”, says “b”, means “c”, but it should be “d” [Polya]
- Frequently begins sentences with “As a physicist…” (as in “As a physicist, I care about the real world, not the logical consequences of the assumption I just made”) [Scott Aaronson]
- When told he is actually a mathematician he thinks: “LOL” and all the mathematician go: “OMFG”. [Peter Sheldrick]
- They think that, since walking forwards gets them from their house to work, walking backwards in the opposite direction must have the same outcome. (Re: the replica method) [James]
- Is interested in creating just one job. [John Sidles]
- Considers chemists to be underqualified physicists, and biologists to be overqualified philatelists. [anonymous]
Amusingly, I know many people (physicists, mostly) who are walking, talking caricature of these. I also know some excellent people in physics departments who certainly are not, and I'm not sure what they do is "physics". I wonder if they think of themselves as physicists...
I know I promised to keep this ridiculous, but I can hardly help myself. So, if you'll permit me a lengthy navel-gazing digression, there's an interesting question here, which has to do with the labels communities of people choose to adopt, and how they view interlopers. For instance, I have no idea whether to call myself an applied mathematician (maybe not), a physicist (almost certainly not, although most of my publications are in physics journals), a computer scientist (still not quite right even though my doctorate is in CS), or what. Informatician sounds like a career in oratory, no one knows what an "applied computer scientist" is, and none of Complex systemsatist, "compleximagician," or statico-phyico-algorithmo-informa-complexicist have that nifty ring to them. (And, for that matter, neither does plecticist.)
With my recent phase change, when people ask what I do, I've taken to simply saying that I'm a "scientist." But, that just encourages them to ask the obvious follow up: What kind of scientist? In some sense, applied mathematician seems colloquially, kind of, maybe, almost like what I do. But, I'm not sure I could teach in a mathematics department, nor would other applied mathematicians call me one of their own. Obviously, these labels are all artificial, but they do matter for hiring, publishing, and general academic success. The complex systems community hasn't achieved a critical-enough mass to assert its own labels for the people who seem to do that kind of work, so, in the meantime, how should we name the practitioners in this field?
Update, 16 April 2007: One colleague suggests "mathematical scientist" as an appropriate moniker, which I tend to also like. Sadly, I'm not sure other scientists would agree that this is a useful label, nor do I expect to see many Departments of Mathematical Science being created in the near future (and similarly for "computational scientist") ... End Update
posted April 15, 2007 08:30 PM in Humor | permalink | Comments (8)
April 01, 2007
Visting U. Maryland Physics
This week I'll be visiting Michelle Girvan, who is now on the faculty of the Physics Department at the University of Maryland - College Park. Michelle tells me that UMD Physics is one of the largest departments in the country, and, looking at their research pages (for instance, here and here), that's not hard to believe.
For those of you in the greater-DC area: in exchange for a week-long suppy of muffins and coffee, I've agreed to give a lunch talk on Thursday, April 5th. I'll post more details closer to the date.
Update, 3 April 2007: My talk will be at 12:15pm in Room 1207 Energy Research Facility (directions), The seminar series' webpage is here. My talk is entitled "Hierarchical decomposition of complex networks," and the abstract is here. End Update
posted April 1, 2007 12:10 AM in Self Referential | permalink | Comments (2)
March 29, 2007
Nemesis or Archenemy
Via Julianne of Cosmic Variance, the rules of the game for choosing your archnemesis. The rules are so great, I reproduce them here, in full.
1. Your archnemesis cannot be your junior. Someone who is in a weaker position than you is not worthy of being your archnemesis. If you designate someone junior as your archnemesis, you’re abusing your power.
2. You cannot have more than one archnemesis. Most of us have had run-ins with scientific groups who range continuous war against all outsiders. They take a scorched earth policy to anyone who is not a member of their club. However, while these people are worthy candidates for being your archnemesis, they are not allowed to have that many archnemeses themselves. If you find that many, many people are your archnemeses, then you’re either (1) paranoid; (2) an asshole; or (3) in a subfield that is so poisonous that you should switch topics. If (1) or (2) is the case, tone it down and try to be a bit more gracious.
3. Your archnemesis has to be comparable to you in scientific ability. It is tempting to despise the one or two people in your field who seem to nab all the job offers, grants, and prizes. However, sometimes they do so because they are simply more effective scientists (i.e. more publications, more timely ideas, etc) or lucky (i.e. wound up discovering something unexpected but cool). If you choose one of these people as an archnemesis based on greater success alone, it comes off as sour grapes. Now, if they nabbed all the job offers, grants, and prizes because they stole people’s data, terrorized their juniors, and misrepresented their work, then they are ripe and juicy for picking as your archnemesis. They will make an even more satisfying archnemesis if their sins are not widely known, because you have the future hope of watching their fall from grace (not that this actually happens in most cases, but the possibility is delicious). Likewise, other scientists may be irritating because their work is consistently confusing and misguided. However, they too are not candidates for becoming your archnemesis. You need to take a benevolent view of their struggles, which are greater than your own. [Ed: Upon recovering my composure after reading this last line, I decided it is, indeed, extremely good advice.]
4. Archnemesisness is not necessarily reciprocal. Because of the rules of not picking fights with your juniors, you are not necessarily your archnemesis’s archnemesis. A senior person who has attempted to cut down a grad student or postdoc is worthy of being an archnemesis, but the junior people in that relationship are not worthy of being the archnemesis of the senior person. There’s also the issue that archnemeses are simply more evil than you, so while they’ll work hard to undermine you, you are sufficiently noble and good that you would not actively work to destroy them (though you would smirk if it were to happen).
Now, what does one do with an archnemesis? Nothing. The key to using your archnemesis effectively is to never, ever act as if they’re your archnemesis (except maybe over beers with a few close friends when you need to let off steam). You do not let yourself sink to their level, and take on petty fights. You do not waste time obsessing about them. Instead, you treat them with the same respect that you would any other colleague (though of course never letting them into a position where they could hurt you, like dealing with a cobra). You only should let your archnemesis serve as motivation to keep pursuing excellence (because nothing annoys a good archnemesis like other people’s success) and as a model of how not to act towards others. You’re allowed to take private pleasure in their struggles or downfall, but you must not ever gloat.
While I’m sure the above sounds so thrilling that you want to rush out and get yourself an archnemesis, if one has not been thrust upon you, count your blessings. May your good fortune continue throughout your career.
In the comment thread, bswift points to a 2004 Esquire magazine piece by Chuck Klosterman on the difference between your (arch)nemesis and your archenemy. Again, quoting liberally.
Now, I know that you’re probably asking yourself, How do I know the difference between my nemesis and my archenemy? Here is the short answer: You kind of like your nemesis, despite the fact that you despise him. If your nemesis invited you out for cocktails, you would accept the offer. If he died, you would attend his funeral and—privately—you might shed a tear over his passing. But you would never have drinks with your archenemy, unless you were attempting to spike his gin with hemlock. If you were to perish, your archenemy would dance on your grave, and then he’d burn down your house and molest your children. You hate your archenemy so much that you try to keep your hatred secret, because you don’t want your archenemy to have the satisfaction of being hated.
Naturally I wonder, Do I have an archnemesis, or an archenemy? Over the years, I've certainly had a few adversarial relationships, and many lively sparring matches, with people at least as junior as me, but they've never been driven by the same kind of deep-seated resentment, and general bad behavior, that these two categories seem to require. So, I count myself lucky that in the fictional story of my life, I've had only "benign" professional relationships - that is, the kind disqualified from nemesis status. However, on the (quantum mechanical) chance that my fictional life takes a dramatic turn, and a figure emerges to play the Mr. Burns to my Homer Simpson, the Newman to my Seinfeld, the Dr. Evil to my Austin Powers, I'll keep these rules (and that small dose of hemlock) handy.
Update, March 30, 2007: Over in the comment section, I posed the question of whether Feynman was Gell-Mann's archnemesis, as I suspected. Having recently read biographies of both men (here and here), it was hard to ignore the subtle (and not-so-subtle) digs that each man made at the other through these stories. A fellow commenter Elliot, who was at Caltech when Gell-Mann received his Nobel confirmed that Feynman was indeed Gell-Mann's archnemesis, not for scientific reasons, but for social ones. Looking back over the rules of the game, Feynman does indeed satisfy all the criteria. Cute.
posted March 29, 2007 12:04 AM in Simply Academic | permalink | Comments (0)
March 25, 2007
The kaleidoscope in our eyes
Long-time readers of this blog will remember that last summer I received a deluge of email from people taking the "reverse" colorblind test on my webpage. This happened because someone dugg the test, and a Dutch magazine featured it in their 'Net News' section. For those of you who haven't been wasting your time on this blog for quite that long, here's a brief history of the test:
In April of 2001, a close friend of mine, who is red-green colorblind, and I were discussing the differences in our subjective visual experiences. We realized that, in some situations, he could perceive subtle variations in luminosity that I could not. This got us thinking about whether we could design a "reverse" colorblindness test - one that he could pass because he is color blind, and one that I would fail because I am not. Our idea was that we could distract non-colorblind people with bright colors to keep them from noticing "hidden" information in subtle but systematic variations in luminosity.
Color blind is the name we give to people who are only dichromatic, rather than the trichromatic experience that 'normal' people have. This difference is most commonly caused by a genetic mutation that prevents the colorblind retina from producing more than two kinds of photosensitive pigment. As it turns out, most mammals are dichromatic, in roughly the same way that colorblind people are - that is, they have a short-wave pigment (around 400 nm) and a medium-wave pigment (around 500 nm), giving them one channel of color contrast. Humans, and some of our closest primate cousins, are unusual for being trichromatic. So, how did our ancestors shift from being di- to tri-chromatic? For many years, scientists have believed that the gene responsible for our sensitivity in the green part of the spectrum (530 nm) was accidentally duplicated and then diverged slightly, producing a second gene yielding sensitivity to slightly longer wavelengths (560 nm; this is the red-part of the spectrum. Amazingly, the red-pigment differs from the green by only three amino acids, which is somewhere between 3 and 6 mutations).
But, there's a problem with this theory. There's no reason a priori to expect that a mammal with dichromatic vision, who suddenly acquired sensitivity to a third kind of color, would be able to process this information to perceive that color as distinct from the other two. Rather, it might be the case that the animal just perceives this new range of color as being one of the existing color sensations, so, in the case of picking up a red-sensitive pigment, the animal might perceive reds as greens.
As it turns out, though, the mammalian retina and brain are extremely flexible, and in an experiment recently reported in Science, Jeremy Nathans, a neuroscientist at Johns Hopkins, and his colleagues show that a mouse (normally dichromatic, with one pigment being slightly sensitive to ultraviolet, and one being very close to our medium-wave, or green sensitivity) engineered to have the gene for human-style long-wave or red-color sensitivity can in fact perceive red as a distinct color from green. That is, the normally dichromatic retina and brain of the mouse have all the functionality necessary to behave in a trichromatic way. (The always-fascinating-to-read Carl Zimmer, and Nature News have their own takes on this story.)
So, given that a dichromatic retina and brain can perceive three colors if given a third pigment, and a trichromatic retina and brain fail gracefully if one pigment is removed, what is all that extra stuff (in particular, midget cells whose role is apparently to distinguish red and green) in the trichromatic retina and brain for? Presumably, enhanced dichromatic vision is not quite as good as natural trichromatic vision, and those extra neural circuits optimize something. Too bad these transgenic mice can't tell us about the new kaleidoscope in their eyes.
But, not all animals are dichromatic. Birds, reptiles and teleost fish are, in fact, tetrachromatic. Thus, after mammals branched off from these other species millions of years ago, they lost two of these pigments (or, opsins), perhaps during their nocturnal phase, where color vision is less functional. This variation suggests that, indeed, the reverse colorblind test is based on a reasonable hypothesis - trichromatic vision is not as sensitive to variation in luminosity as dichromatic vision is. But why might a deficient trichromatic system (retina + brain) would be more sensitive to luminal variation than a non-deficient one? Since a souped-up dichromatic system - the mouse experiment above - has most of the functionality of a true trichromatic system, perhaps it's not all that surprising that a deficient trichromatic system has most of the functionality of a true dichromatic system.
A general explanation for both phenomena would be that the learning algorithms of the brain and retina organize to extract the maximal amount of information from the light coming into the eye. If this happens to be from two kinds of color contrast, it optimizes toward taking more information from luminal variation. It seems like a small detail to show scientifically that a deficient trichromatic system is more sensitive to luminal variation than a true trichromatic system, but this would be an important step to understanding the learning algorithm that the brain uses to organize itself, developmentally, in response to visual stimulation. Is this information maximization principle the basis of how the brain is able to adapt to such different kinds of inputs?
G. H. Jacobs, G. A. Williams, H. Cahill and J. Nathans, "Emergence of Novel Color Vision in Mice Engineered to Express a Human Cone Photopigment", Science 315 1723 - 1725 (2007).
P. W. Lucas, et al, "Evolution and Function of Routine Trichromatic Vision in Primates", Evolution 57 (11), 2636 - 2643 (2003).
posted March 25, 2007 10:51 AM in Evolution | permalink | Comments (3)
February 15, 2007
Fast-modularity made really fast
The other day on the arxiv mailing, a very nice paper appeared (cs.CY/0702048) that optimizes the performance of the fast-modularity algorithm that I worked on with Newman and Moore several years ago. Our algorithm's best running time was O(n log^2 n) on sparse graphs with roughly balanced dendrograms, and we applied it to a large network of about a half million vertices (my implementation is available here).
Shortly after we posted the paper on the arxiv, I began studying its behavior on synthetic networks to understand whether a highly right-skewed distribution of community sizes in the final partition was a natural feature of the real-world network we studied, or whether it was caused by the algorithm itself [1]. I discovered that the distribution probably was not entirely a natural feature because the algorithm almost always produces a few super-communities, i.e., clusters that contain a large fraction of the entire network, even on synthetic networks with no significant community structure. For instance, in the network we analyzed, the top 10 communities account for 87% of the vertices.
Wakita and Tsurumi's paper begins with this observation and then shows that the emergence of these super-communities actually slows the algorithm down considerably, making the running time more like O(n^2) than we would like. They then show that by forcing the algorithm to prefer to merge communities of like sizes - and thus guaranteeing that the dendrogram it constructs will be fairly balanced - the algorithm achieves the bound of essentially linear running time that we proved in our paper. This speed-up yields truly impressive results - they cluster a 4 million node network in about a half an hour - and I certainly hope they make their implementation available to the public. If I have some extra time (unlikely), I may simply modify my own implementation. (Alternatively, if someone would like to make that modification, I'm happy to host their code on this site.)
Community analysis algorithm proposed by Clauset, Newman, and Moore (CNM algorithm) finds community structure in social networks. Unfortunately, CNM algorithm does not scale well and its use is practically limited to networks whose sizes are up to 500,000 nodes. The paper identifies that this inefficiency is caused from merging communities in unbalanced manner. The paper introduces three kinds of metrics (consolidation ratio) to control the process of community analysis trying to balance the sizes of the communities being merged. Three flavors of CNM algorithms are built incorporating those metrics. The proposed techniques are tested using data sets obtained from existing social networking service that hosts 5.5 million users. All the methods exhibit dramatic improvement of execution efficiency in comparison with the original CNM algorithm and shows high scalability. The fastest method processes a network with 1 million nodes in 5 minutes and a network with 4 million nodes in 35 minutes, respectively. Another one processes a network with 500,000 nodes in 50 minutes (7 times faster than the original algorithm), finds community structures that has improved modularity, and scales to a network with 5.5 million.
K. Wakita and T. Tsurumi, "Finding Community Structure in Mega-scale Social Networks." e-print (2007) cs.CY/0702048
Update 14 April 2008: Ken Wakita tells me that their code is now publicly available online.
-----
[1] Like many heuristics, fast-modularity achieves its speed by being highly biased in the set of solutions it considers. See footnote 7 in the previous post. So, without knowing more about why the algorithm behaves in the way it does, a number of things are not clear, e.g., how close to the maximum modularity the partition it returns is, how sensitive its partition is to small perturbations in the input (removing or adding an edge), whether supplementary information such as the dendrogram formed by the sequence of agglomerations is at all meaningful, whether there is an extremely different partitioning with roughly the same modularity, etc. You get the idea. This is why it's wise to be cautious in over-interpreting the output of these biased methods.
posted February 15, 2007 08:23 AM in Computer Science | permalink | Comments (0)
December 26, 2006
2006: a year in review
It would be hard for this blog to break a larger number of blogging traditions. But, these last few days of 2006 do seem like an appropriate time to look back over the year that was 2006 and remember some of the things that have happened. So, in my best stereotypical blogging fashion, here is 2006, in review.
Number of published papers on which I was first author or a major contributor: 3
Number of papers currently under review: 2
Number of manuscripts near completion: 3
Number of manuscripts reviewed for various journals / conferences: >18
Number of research talks given: 12
Number of conferences / workshops attended: 4
Number of those at which I delivered a research talk: 4
Conferences organized: 1
Program committees sat on: 1
Dissertations defended: 1
Graduation speeches given: 1
Blog entries written: 55 (this number is depressingly low)
Number of emails sent: >1316
Number of (non-spam) emails received: >4635 (these numbers are depressingly high)
Number of fun trips with friends / family: 16
Number of movies via Netflix: 69
Number of major life / career decisions made: 1
posted December 26, 2006 01:20 AM in Self Referential | permalink | Comments (0)
December 19, 2006
Phase change
 This past weekend I graduated with distinction with my doctorate from the University of New Mexico's Department of Computer Science. My advisor Cristopher Moore hooded me at the main Commencement ceremony on Friday, and on Saturday, the School of Engineering had its own smaller (and nicer) Convocation ceremony for its graduates. I was invited to be the graduate speaker at this event, and I made a few brief remarks that you can read here.
This past weekend I graduated with distinction with my doctorate from the University of New Mexico's Department of Computer Science. My advisor Cristopher Moore hooded me at the main Commencement ceremony on Friday, and on Saturday, the School of Engineering had its own smaller (and nicer) Convocation ceremony for its graduates. I was invited to be the graduate speaker at this event, and I made a few brief remarks that you can read here.
It's been an intense and highly educational four and a half years, but it's nice to finally be done.
posted December 19, 2006 12:36 PM in Self Referential | permalink | Comments (1)
October 11, 2006
Hierarchy in networks
After several months of silence on it, I've finally posted a new paper (actually written more than 5 months ago!) on the arxiv about the hierarchical decomposition of network structure. I presented it at the 23rd International Conference on Machine Learning (ICML) Workshop on Social Network Analysis in June.
Aaron Clauset, Cristopher Moore, M. E. J. Newman, "Structural Inference of Hierarchies in Networks", to appear in Lecture Notes in Computer Science (Springer-Verlag). physics/0610051
One property of networks that has received comparatively little attention is hierarchy, i.e., the property of having vertices that cluster together in groups, which then join to form groups of groups, and so forth, up through all levels of organization in the network. Here, we give a precise definition of hierarchical structure, give a generic model for generating arbitrary hierarchical structure in a random graph, and describe a statistically principled way to learn the set of hierarchical features that most plausibly explain a particular real-world network. By applying this approach to two example networks, we demonstrate its advantages for the interpretation of network data, the annotation of graphs with edge, vertex and community properties, and the generation of generic null models for further hypothesis testing.
posted October 11, 2006 07:44 PM in Self Referential | permalink | Comments (0)
July 20, 2006
One more hurdle, cleared.
Today, I passed my dissertation defense, with distinction. Thank you to everyone who helped me get to, and past, this point in my career.
To celebtrate, this weekend I'm off to Las Vegas to complete my two-part homage to the gods of chance. Each part of the homage involves a pilgrimage to a holy site and a ritualistic sacrifice of 20 units of currency on the alter of probability. The first part was two summers ago, when I offered 20 euro to the gods at Monte Carlo, who rewarded me with a repayment in kind. This weekend, I'll offer 20 dollars to the gods of Las Vegas, and see if they're as nice as their French counterparts.
{kind=link}
Update, July 24: The gods of chance who reside in Las Vegas are decidedly more callow than their fellows in Monte Carlo, which is to say that I lost my $20.
posted July 20, 2006 11:28 AM in Self Referential | permalink | Comments (3)
July 10, 2006
That career thing
I'm sure this piece of advice to young scientists by John Baez (of quantum gravity fame) is old news now (3 years on). But, seeing as it was written before I was paying attention to this kind of stuff myself, and it seems like quite good advice, here is it, in a nutshell:
1. Read voraciously, ask questions, don't be scared of "experts", and figure out what are the good problems to work on in your field.
2. Go the most prestigious school, and work with the best possible advisor.
3. Publish often and publish stuff people will want to read (and cite).
4. Go to conferences and give good, memorable talks.
Looking back over my success, so far, I think I've done a pretty good job on most of these things. His advice about going to a prestigious place seems to be more about getting a good advisor - I suppose that in physics, being a very old field, the best advisors can only be found at the most prestigious places. But, I'm not entirely convinced that this is true for the interdisciplinary mashup, which includes complex networks and the other things I like to study, yet...
posted July 10, 2006 12:50 AM in Simply Academic | permalink | Comments (3)
June 29, 2006
A "reverse" color test
In the past few days, I've received a number of emails from people who took the reverse color-blind test on this site. Normally, I've gotten a sparse, but steady stream of emails about it over the years, but the recent deluge appears to be due to Clive Thompson's blog entry on the topic. (Thanks Clive!) For those of you who are curious, here's the story behind the test.
About six years ago over lunch, my friend Nick Yee and I were chatting about color vision and the differences between what a "color sighted" person can see and what a "color blind" person can see. I represented the former, while Nick represented the latter. Now, there are several different kinds of color-blindness, and Nick happens to have the kind that makes him fairly insensitive to variations in red hue, so-called red-green color blindness. One of the things he complained about was the color blind tests that hide images in the hue of an image so that color sighted people can see the image, while color blind people cannot. We mused about whether you could make a reverse test where we hid an image in a way that color blind people could see, but color sighted people could not. But, if color blindness is purely a deficit, how can this be done?
In most color-sighted people, the parts of the retina that are sensitive to the hue of red seem to be a little more sensitive to intense red hues than the corresponding parts for blue and green. So, our idea was that we could overwhelm (saturate) the red channel in color-sighted people and thus hide information in an independent channel (luminosity) that red-green color-blind individuals would be able to detect. That evening, we each went to work in photoshop and produced some test images to try out on each other. My images and writeup are on this site (here), while Nick maintains his own page here.
What I've learned over the years, from emails by people finding and taking the test, is that a person's sensitivity to red hue varies tremendously from individual to individual. Most people can see the corner of the secret image in the first picture, but few can see the remainder. Some individuals have a more balanced sensitivity to hues, and their eyes aren't fooled by the intensity of the red - they can see the secret image just fine, even though they can also see the full color spectrum (these people seem to be quite rare). Some people have trouble with the second picture - their eyes are confused by the heterogeneous structure of hue - while others have no trouble at all. Even a color-sighted person can see the secret image in the second picture if they know what to look for, that is, if they have a clear expectation about what's hidden and where to look for it, then they can pick out the subtle variations in luminosity.
I'm very curious to hear from someone who knows more about how the retina works, where this variation comes from, and what other possibilities exist for making a better "reverse" color test. For those of you coming from Collision Detection and taking the test, feel free to leave a comment about your experience with the test.
Update, 21 July 2006: The test was also featured recently on Veronica Magazine's Netnews. Welcome folks from the Netherlands!
Update, 13 March 2007: Turns out that the test was dugg sometime around last July, which explains some of the spike in traffic the test received around that time. The Digg comments are kind of amusing - many people discovered that their laptop monitors let them see the "hidden" images even though they aren't colorblind.
posted June 29, 2006 11:53 PM in Self Referential | permalink | Comments (7)
March 07, 2006
Running a conference (redux)
 Once again, for the past eight months or so, I've been heavily involved in running a small conference. The second annual Computer Science UNM Student Conference (CSUSC) happened this past Friday and was, in every sense of the word, a resounding success. Originally, this little shindig was conceived as a way for students to show off their research to each other, to the faculty, and to folks at Sandia National Labs. As such, this year's forum was just as strong as last year's inaugural session, having ten well-done research talks and more than a dozen poster presentations. Our keynote address was delivered by the friendly and soft-spoken David Brooks (no, not that one) from Harvard University, on power efficiency in computing. (Naturally, power density has been an important constraint on computing for a long time.)
Once again, for the past eight months or so, I've been heavily involved in running a small conference. The second annual Computer Science UNM Student Conference (CSUSC) happened this past Friday and was, in every sense of the word, a resounding success. Originally, this little shindig was conceived as a way for students to show off their research to each other, to the faculty, and to folks at Sandia National Labs. As such, this year's forum was just as strong as last year's inaugural session, having ten well-done research talks and more than a dozen poster presentations. Our keynote address was delivered by the friendly and soft-spoken David Brooks (no, not that one) from Harvard University, on power efficiency in computing. (Naturally, power density has been an important constraint on computing for a long time.)
Having organized this conference twice now, I have a very healthy respect for how much time is involved in making such an event a success. Although most of one's time is spent making sure all the gears are turning at the proper speeds (which includes, metaphorically, keeping the wheels greased and free of obstructions) so that each part completes in time to hand-off to the next, I'm also happy with how much of a learning experience its seems to have been for everyone involved (including me). This year's success was largely due to the excellent and tireless work of the Executive Committee, while, I'm confident saying that, all of the little hiccoughs we encountered were oversights on my part. Perhaps next year, those things will be done better by my successor.
But, the future success of the CSUSC is far from guaranteed: the probability of a fatal dip in the inertia of student interest in organizing it is non-trivial. This is a risk, I believe, that every small venue faces, since there are only ever a handful of students interested in taking time away from their usual menu of research and course work to try their hand at professional service. I wonder, What fraction of researchers are ever involved in organizing a conference? Reviewing papers is a standard professional duty, but the level of commitment required to run a conference is significantly larger - it takes a special degree of willingness (masochism?) and is yet another of the many parts of academic life that you have to learn in the trenches. For the CSUSC, I simply hope that the goodness that we've created so far continues on for a few more years, and am personally just glad we had such a good run over the past two.
With this out of the way, my conference calendar isn't quite empty, and is already rapidly refilling. Concurrent to my duties to the CSUSC, I've also been serving on the Program Committee for the 5th International Workshop on Experimental Algorithms (WEA), a medium-sized conference on the design, analysis and implementation of algorithms. An interesting experience, in itself, in part for broadening my perspective on the kind of research being done in algorithms. In May, always my busiest month for conferences, I'll be attending two events on network science. The first is CAIDA's Workshop on Internet Topology (WIT) in San Diego, while the second is the NetSci 2006 in Bloomington, Indiana.
posted March 7, 2006 04:37 AM in Simply Academic | permalink | Comments (0)
March 01, 2006
The scenic view
In my formal training in physics and computer science, I never did get much exposure to statistics and probability theory, yet I have found myself consistently using them in my research (partially on account of the fact that I deal with real data quite often). What little formal exposure I did receive was always in some specific context and never focused on probability as a topic itself (e.g., statistical mechanics, which could hardly be called a good introduction to probability theory). Generally, my training played-out in the crisp and clean neighborhoods of logical reasoning, algebra and calculus, with the occasional day-trip to the ghetto of probability. David Mumford, a Professor of Mathematics at Brown University, opines about ongoing spread of that ghetto throughout the rest science and mathematics, i.e., how probability theory deserves a respect at least equal to that of abstract algebra, in a piece from 1999 on The Dawning of the Age of Stochasticity. From the abstract,
For over two millennia, Aristotle's logic has rules over the thinking of western intellectuals. All precise theories, all scientific models, even models of the process of thinking itself, have in principle conformed to the straight-jacket of logic. But from its shady beginnings devising gambling strategies and counting corpses in medieval London, probability theory and statistical inference now emerge as better foundations for scientific models ... [and] even the foundations of mathematics itself.
It may sound it, but I doubt that Mumford is actually overstating his case here, especially given the deep connection between probability theory, quantum mechanics (c.f. the recent counter-intuitive result on quantum interrogation) and complexity theory.
A neighborhood I'm more familiar with is that of special functions; things like the Gamma distribution, the Riemann Zeta function (a personal favorite), and the Airy functions. Sadly, these familiar friends show up very rarely in the neighborhood of traditional computer science, but instead hang out in the district of mathematical modeling. Robert Batterman, a Professor of Philosophy at Ohio State University, writes about why exactly these functions are so interesting in On the Specialness of Special Functions (The Nonrandom Effusions of the Divine Mathematician).
From the point of view presented here, the shared mathematical features that serve to unify the special functions - the universal form of their asymptotic expansions - depends upon certain features of the world.
(Emphasis his.) That is, the physical world itself, by presenting a patterned appearance, must be governed by a self-consistent set of rules that create that pattern. In mathematical modeling, these rules are best represented by asymptotic analysis and, you guessed it, special functions, that reveal the universal structure of reality in their asymptotic behavior. Certainly this approach to modeling has been hugely successful, and remains so in current research (including my own).
My current digs, however, are located in the small nexus that butts up against these neighborhoods and those in computer science. Scott Aaronson, who occupies an equivalent juncture between computer science and physics, has written several highly readable and extremely interesting pieces on the commonalities he sees in his respective locale. I've found them to be a particularly valuable way to see beyond the unfortunately shallow exploration of computational complexity that is given in most graduate-level introductory classes.
In NP-complete Problems and Physical Reality Aaronson looks out of his East-facing window toward physics for hints about ways to solve NP-complete problems by using physical processes (e.g., simulated annealing). That is, can physical reality efficiently solve instances of "hard" problems? Although he concludes that the evidence is not promising, he points to a fundamental connection between physics and computer science.
Then turning to look out his West-facing window towards computer science, he asks Is P Versus NP Formally Indepenent?, where he considers formal logic systems and the implications of Godel's Incompleteness Theorem for the likelihood of resolving the P versus NP question. It's stealing his thunder a little, but the most quotable line comes from his conclusion:
So I'll state, as one of the few definite conclusions of this survey, that P \not= NP is either true or false. It's one or the other. But we may not be able to prove which way it goes, and we may not be able to prove that we can't prove it.
There's a little nagging question that some researchers are only just beginning to explore, which is, are certain laws of physics formally independent? I'm not even entirely sure what that means, but it's an interesting kind of question to ponder on a lazy Sunday afternoon.
There's something else embedded in these topics, though. Almost all of the current work on complexity theory is logic-oriented, essentially because it was born of the logic and formal mathematics of the first half of the 20th century. But, if we believe Mumford's claim that statistical inference (and in particular Bayesian inference) will invade all of science, I wonder what insights it can give us about solving hard problems, and perhaps why they're hard to begin with.
I'm aware of only anecdotal evidence of such benefits, in the form of the Survey Propagation Algorithm and its success at solving hard k-SAT formulas. The insights from the physicists' non-rigorous results has even helped improve our rigorous understanding of why problems like random k-SAT undergo a phase transition from mostly easy to mostly hard. (The intuition is, in short, that as the density of constraints increases, the space of valid solutions fragments into many disconnected regions.) Perhaps there's more being done here than I know of, but it seems that a theory of inferential algorithms as they apply to complexity theory (I'm not even sure what that means, precisely; perhaps it doesn't differ significantly from PPT algorithms) might teach us something fundamental about computation.
posted March 1, 2006 02:32 PM in Interdisciplinarity | permalink | Comments (0)
February 07, 2006
Dodgeball
Dodgeball is social software done right: an easy interface, sensible (and voluntary) rules of participation and convenient for the mobile world of youth. (Would you be surprised to know that Google bought Dodgeball in 2005? Didn't think so.) Why isn't this ubiquitous? Probably because it needs a critical mass of users before it becomes a valuable experience to them all. Thus, their tag line should instead be "Dodgeball - it's everywhere you want to be."
posted February 7, 2006 12:21 AM in Self Referential | permalink | Comments (0)
January 18, 2006
7x7
Normally, I detest the kind of chain letters that circulate over email, where you're supposed to answer a (long) series of questions about your personality and life, and then forward it to all of your friends. But, since I've been specifically invited, and this seems a relatively benign version of the meme, here goes (and yes, it took me far too long to come up with seven entries for each category - I'm just a bit slow on some things).
1. Seven things to do before I die
(i) See every country on this planet
(ii) Learn to play the guitar
(iii) Take my (eventual) kids to six different continents
(iv) Live in New York City
(v) Write a book (a textbook on modeling complex systems seems the most likely)
(vi) Be a tenured professor
(vii) Bank a million dollars
2. Seven things I cannot do
(i) Anything related to being musical
(ii) Program a VCR
(iii) Speak a language other than English (much to my shame)
(iv) Give up my optimism, or my liberalism
(v) Get worked up about little things
(vi) Relate to "flakey" people
(vii) Relate to the culture of sports television
3. Seven things that attract me to [Albuquerque]
(i) The wilderness just beyond the city limits
(ii) Restaurants like The Artichoke Cafe
(iii) Always being able to see mountains when I'm outside
(iv) The bright sun and broad blue sky
(v) Leaving town
(vi) The proximity to places like LANL and SFI
(vii) The contrast with the East Coast
4. Seven things I say most often
(i) "I read this [study / book / paper / article] recently"
(ii) "Remember that conversation we had [X days / months / years] ago, well I was thinking about it and"
(iii) "The movie was great, except for the parts where they ignored the laws of physics"
(iv) "Um, well, let's see"
(v) [insert play on words here]
(vi) "I'm not sure", or "I don't know"
(vii) "What this means is that"
5. Seven books (or series) that I love
(i) V for Vendetta, Moore and Lloyd
(ii) Lord of the Rings, Tolkien
(iii) Blade of the Immortal, Samura
(iv) The Meaning of It All, Feynman
(v) Raising Cain, Kindlon and Thompson
(vi) Kiss of the Spiderwoman, Puig
(vii) The Atlantic Monthly
6. Seven movies that I watch over and over again (or would if I had the time)
(i) Dr. Strangelove
(ii) Before Sunset
(iii) Casablanca
(iv) The Matrix
(v) Bladerunner
(vi) Office Space
(vii) Some Like It Hot
7. Seven people I want to join in, too.
(i) Tim Burke
(ii) danah boyd
(iii) The folks at Fafblog!
(iv) Terry McMahon
(v) Nick Yee
(vi) Brad Delong
(vii) You, whomever you are
posted January 18, 2006 05:16 PM in Self Referential | permalink | Comments (0)
November 09, 2005
The beauty of automation
I should really blog at much greater length about the beauty of the ability to automate simple (or, if you're clever, extremely complex) tasks through computer programming. Of course, with beauty comes ugliness. Every systems administrator (or at least every single one that I've ever known) will tell you that will being able to automate the maintenance of their various computers is wonderful, it is also what allows one malicious person to write a program that exploits a software vulnerability and thus enable any 13-year old "script kiddie" to be just as dangerous without half the technical knowledge.
But that point will have to wait until later. Tonight, I discovered Yahoo!'s FareChaser, which automates the searching of several airfare websites (the fine print indicates that it is only "participating partners" which suggests that money is changing hands for this service; however, the fact that orbitz.com is on the list muddies this hypothesis somewhat since Orbitz is ostensibly the same kind of automated search (what a lovely idea, search engines searching each other for results)). Why is this tool any better than the old crop of such clearing houses that have been around for years now? Because it appears to search the airlines' websites themselves, which, in my broad experience as a frequent flier, often have cheaper flights at different times than places like Orbitz or Travelocity. So, here's to technology making life even more convenient than it is now and saving me the time of hitting those websites individually.
On a related note, I like that Yahoo!, Microsoft and Google are all competing quite vigorously to create compelling online applications for users (typically using Ajax, a really great hack of a technology). All the better for us, and, ultimately, the better for them, too. No one likes a stagnating, entrenched corporation bent on extracting ever greater revenue from the same (formerly compelling but now just prosaic) offerings. Oh, I'm not thinking of anyone in particular. Really.
posted November 9, 2005 10:35 PM in Self Referential | permalink | Comments (1)
September 13, 2005
TravelBlog: Making the summit of Longs Peak
Weekend before last, over the long Labor Day weekend, I trekked north to Rocky Mountain National Park with friend Adriane Irwin, Lauren Meyer and two of their friends Shawn and Cheryl. Our intention was to summit Longs Peak, the tallest non-technical summit in the lower 48 states. Longs Peak's summit stands at 14,259 feet (4321 meters) above sea level. This elevation is significantly higher than my usual elevation of roughly 5,314 feet (1,610 meters; and I'd only been at that elevation for about three weeks since prior to that, I'd been at sea level in New York City), and I was not positive that I would make it to the top.
And yet, I did. Longs Peak was my first 14'er and probably not my last. As I mentioned to my friend Jen from the climbing gym this evening, I've been interested in doing serious outdoors stuff for a long time, but have simply not had a set of friends who were also interested (this makes me wonder if for some other reason I tend not to be selective for crazy adventurous friends). On the other hand, as I mentioned to Keith and Angie this afternoon, I'm much more interested in having good company along for those adventures than I am in crossing them off some abstract list of accomplishments. Still, it will be nice to have both!
Our summit attempt of Longs Peak began after we lucked out and landed a camp site in the small camp ground near the trailhead. We prepped our gear, had a snack and then hit the sack for a few hours. We set the alarm for 1:10am, although I slept restlessly and ended up awake at 12:50am, waiting for go-time to arrive. After assembling our gear, we picked up our two new friends Jake and Luke (brothers who had driven-in the day before from Indiana), and made for the trailhead. Adriane, betraying her excitement, set a quick pace for the first few miles of the hike. As we crossed the tree-line, we could see the lights from Denver in the distance, and the looming darkness of Longs Peak miles away above us.
 It wasn't long before I volunteered for lead-duty. This was partially on account of Adriane finally relinquishing the position herself and partially because I wanted to set a slower pace. Above the tree-line, the steps of the trail were tiring, and I was a little concerned that the altitude would wear me out quickly. And so, I led our group of seven along the trail as it snaked its way up the mountain, through the lower tundra. At the break for Chasm Lake, we rested briefly before pushing on to Boulder Field. The cold of the night air and the heat of the hiking kept the girls constantly shifting their layers. I was comfortable in my polypro and nylon layers, content to roll-up or roll-down my sleeves in order to shed a few extra degrees of heat.
It wasn't long before I volunteered for lead-duty. This was partially on account of Adriane finally relinquishing the position herself and partially because I wanted to set a slower pace. Above the tree-line, the steps of the trail were tiring, and I was a little concerned that the altitude would wear me out quickly. And so, I led our group of seven along the trail as it snaked its way up the mountain, through the lower tundra. At the break for Chasm Lake, we rested briefly before pushing on to Boulder Field. The cold of the night air and the heat of the hiking kept the girls constantly shifting their layers. I was comfortable in my polypro and nylon layers, content to roll-up or roll-down my sleeves in order to shed a few extra degrees of heat.
Although this hike was filled with spectacular visuals, one of my favorites was, from near Boulder Field, looking back down the trail during the blackness of night. Tracing the twists and turns of the trail were a train of bright points, bobbing with the motion of hikers as they made their way over the foothills. The quietude of the moment combined with the solemnness of the dancing lights made me think of a pilgrimage, in which dutiful worshippers made their way to the mountain sanctuary to offer their prayers to the gods that live within the mountain. Although I doubt any of the hikers on the trail was doing that exactly, among those serious enough to summit Longs Peak (or otherwise revel in the beauty and ruggedness of nature), I can't help but feel that there was a subtle religious subtext to our trek.
 At the Boulder Field rest stop, we spotted the sun beginning to peak over the horizon, and our surroundings were visibly more light. We hardly needed our headlamps as we began to pick our way through the large rubble toward to Keyhole. It was near this milestone point that the sun finally broke away from the shadow of the nearby mountain and seared the night sky with orange, red and yellow fire. Given my surroundings, it was one of the most beautiful sunrises I have ever seen, and had I not been with company, I likely would have found a comfortable rock to park myself upon so as to soak it up for a spell.
At the Boulder Field rest stop, we spotted the sun beginning to peak over the horizon, and our surroundings were visibly more light. We hardly needed our headlamps as we began to pick our way through the large rubble toward to Keyhole. It was near this milestone point that the sun finally broke away from the shadow of the nearby mountain and seared the night sky with orange, red and yellow fire. Given my surroundings, it was one of the most beautiful sunrises I have ever seen, and had I not been with company, I likely would have found a comfortable rock to park myself upon so as to soak it up for a spell.
As we turned through the Keyhole, I laid eyes on the beginning of the difficult part of the hike. James had described this section as being a three-foot wide ledge with a thousand foot drop on one side - it wasn't nearly that bad, but the steep slope off to my right certainly made me more cautious as we began to pick our way through the jagged rocks, hugging the slope while following the painted bulls-eyes that led us forward. From here-on-out, I was careful with my hands, making sure that I always had my balance, and always had one good hand-hold in case I lost my balance. It was also at this point, at 13,000ft, that I began the feel the altitude in earnest. I developed a slight headache and a slight shortness of breath, both of which progressed as we climbed the remaining 1200 feet to the summit.
 The bouncing bulls-eyes led us to what's known as the Trough, which is truly the worst part of the hike. With an elevation gain of perhaps close to 700 feet, the Trough is filled with boulders, gravel and dirt, and the footing was significantly less sure than on the jagged but solid rock we had just crossed. It was here that I began to fall behind the rest of the group, and here that Adriane and Lauren began to push ahead. Deciding that being safe was more important to me than keeping up with the group, I let the distance grow until it was only Luke and I at the top of the Trough, while the rest were on to the Narrows. Luke and I hadn't spoken much on the hike up, but as we sat at the top of the Trough, gazing out at the breathtakingly beautiful and immensely expansive landscape, we commiserated about the difficulty of the altitude and the Trough. I could tell he was reluctant to go on, and so I consoled him. Finally, he said that this was the most beautiful spot on Earth he'd ever seen and that he was going to stay right here.
The bouncing bulls-eyes led us to what's known as the Trough, which is truly the worst part of the hike. With an elevation gain of perhaps close to 700 feet, the Trough is filled with boulders, gravel and dirt, and the footing was significantly less sure than on the jagged but solid rock we had just crossed. It was here that I began to fall behind the rest of the group, and here that Adriane and Lauren began to push ahead. Deciding that being safe was more important to me than keeping up with the group, I let the distance grow until it was only Luke and I at the top of the Trough, while the rest were on to the Narrows. Luke and I hadn't spoken much on the hike up, but as we sat at the top of the Trough, gazing out at the breathtakingly beautiful and immensely expansive landscape, we commiserated about the difficulty of the altitude and the Trough. I could tell he was reluctant to go on, and so I consoled him. Finally, he said that this was the most beautiful spot on Earth he'd ever seen and that he was going to stay right here.
Resolving to push on myself, I bid him farewell and said that perhaps we'd meet up again at the Keyhole on the way down. And then it was into the Narrows. James' description was slightly more accurate here, but still there were plenty of outcroppings and formations to pick your way through - I never felt in danger, but still, I respected the distance between myself and the bottom of the mountain to my right. For this section, I was joined by a young woman who came up behind me in the Trough. We would hike for a period and then rest, then hike and rest, etc. We chatted amicably occasionally, commenting on the altitude. Finally, at the point where the Narrows meets the Homestretch, she pushed forward, and I was again left behind.
 The Homestretch is much like the Trough, except without the loose footing. Another 600 foot vertical rise on a steep slope. Slowly, with hikers from behind passing often enough to remind me that my body was suffering, I neared the summit. At about 8:40am, I reached the top and found the rest of the group in high spirits, having been there for a little more than half an hour already. We snapped the requisite group photos, shots of Chasm Lake from above, pictures of the clouds rolling in, and a few more shots of each other. As the weather turned cold and the summit was enveloped in a white fog, we began our descent.
The Homestretch is much like the Trough, except without the loose footing. Another 600 foot vertical rise on a steep slope. Slowly, with hikers from behind passing often enough to remind me that my body was suffering, I neared the summit. At about 8:40am, I reached the top and found the rest of the group in high spirits, having been there for a little more than half an hour already. We snapped the requisite group photos, shots of Chasm Lake from above, pictures of the clouds rolling in, and a few more shots of each other. As the weather turned cold and the summit was enveloped in a white fog, we began our descent.
Although going up the mountain was difficult on account of the physicality of raising your body nearly a mile, going down was difficult for the pounding on the knees. It was made no less complicated by the large number of people we met going in the opposite direction - Jen, who has done Longs before, said that starting at 2:00am was excessive, but I'm glad we did because it made the ascent significantly less crowded. With the lightness of day around us, I took many pictures of the descent, chronicling the way-points and landmarks and vistas. It wasn't until about half way down the lower tundra that my knees truly began to ache from the constant pounding on unforgiving stone, and I began to take more frequent breaks.
 Again, I fell behind the group as a result. This time, however, it was more intentional. When I'm out in nature like this, I like to take a little bit of time to be completely alone and simply soak it all in. To try to open every pore of my body and absorb the beauty and serenity that surrounds me, to try to store it up for all the days I'll spend away from it, imbedded in a complicated and noisy jungle of concrete and asphalt. Satiated, I wore a big and goofy smile as I bounced down the trail after the group ahead of me. We were briefly reunited at the break to Chasm Lake, where I captured a nice panorama Longs. Finally, at close to 2:15pm, twelve strenuous and exhausting hours later, I made it back to our campsite, tired but happy.
Again, I fell behind the group as a result. This time, however, it was more intentional. When I'm out in nature like this, I like to take a little bit of time to be completely alone and simply soak it all in. To try to open every pore of my body and absorb the beauty and serenity that surrounds me, to try to store it up for all the days I'll spend away from it, imbedded in a complicated and noisy jungle of concrete and asphalt. Satiated, I wore a big and goofy smile as I bounced down the trail after the group ahead of me. We were briefly reunited at the break to Chasm Lake, where I captured a nice panorama Longs. Finally, at close to 2:15pm, twelve strenuous and exhausting hours later, I made it back to our campsite, tired but happy.
posted September 13, 2005 10:37 PM in Travel | permalink | Comments (1)
August 29, 2005
A return to base.
I returned to New Mexico about two weeks ago, and have, I think, almost gotten my loose ends from the summer tied up to the point that I can consider blogging again on a regular basis. I will certainly be blogging about my newfound insight into the dark world of the credit card industry, the similarities between academia and consulting, and other edifying topics.
Also, as a slight update, the SIAM news article on my work with Cristopher Moore, and in turn with David Kempe and Dimitris Achlioptas on analyzing the bias of the tools that we use to map the Internet has finally appeared online.
Additionally, Philip Ball, who has written about my work on the statistics of terrorism before (here, and here, both for Nature News), has penned another article for The Guardian that discusses Neil Johnson's recent preprint and again Maxwell Young's work with me on terrorism.
posted August 29, 2005 12:54 PM in Blog Maintenance | permalink | Comments (0)
July 10, 2005
On being average (part 2)
Last Friday, I interviewed with a writer for the Albuquerque Tribune about my appearance on Average Joe IV. The story should appear in the Tribune on Monday or Tuesday. I'll post a link to the story when it's up.
posted July 10, 2005 12:20 PM in Self Referential | permalink | Comments (1)
July 04, 2005
On being average
For your entertainment, Average Joe IV.
posted July 4, 2005 08:34 PM in Self Referential | permalink | Comments (7)
May 31, 2005
On the brain and its prostitution
This summer, I will post on a slightly lighter schedule as I will be spending most of my time (although perhaps not my mental energy) exploring the new field of financial consulting. Yes, I have decided to prostitute my brain to the feudal lords of money in an attempt to both hedge my bet on academia (and the glorious riches and fame that can accompany such a career) with a modest foray into the respected and venerable industry of hiring my smarts out to the highest bidder (who, in this case, happens to be a very large financial company that has hired the New York City consulting firm that I'm working for), and to supplement my burgeoning graduate student stipend. So, wish me luck and perhaps offer a quick prayer to Dionysus that I won't contract any debilitating diseases from my effective prostitution, and perhaps will even come away with some valuable skills. Oddly, I'm not entirely convinced that academia and business are that different... this is a topic that I should blog at some point.
posted May 31, 2005 11:16 PM in Self Referential | permalink | Comments (0)
May 17, 2005
Reality as just another kind of media
danah boyd has an excellent observation piece on her blog apophenia in which she discusses the problems with connecting together physical and digital persona for the same person. From the entry:
... Given Aronsons' work (in brief, first impressions matter and are near impossible to overturn), coarse data is highly problematic. The thing about blogging is that it appears to be rich data, not coarse data. Yet, at the same time, how are the mental models of an individual connected to them? And worse, how do our models based on digital interactions fail to prepare us for what happens when we interact? This has huge implications on our ability to get to know people online.
As I think all of we who make an effort to project ourselves digitally wonder, What impression do people have who, after Googling me, read my website, my blog and my articles? Beyond danah's fascination, which I also share, of the disconnect between physical and digital persona, there are other potential disconnects to consider. As academics, we communicate ideas through our technical writing, and there are several researchers whom I have met after become very familiar with the results of their research. My mental image of them is inevitably far off. This point danah raises is particularly interesting to me, for a reason that will become obvious toward the end of June. Different personas, different media, different false impressions.
posted May 17, 2005 10:28 PM in Self Referential | permalink | Comments (0)
April 09, 2005
TravelBlog: Tokyo, the New York of the East...
Actually, a more apt statement would be New York is the Tokyo of the West. (For some great pictures of Tokyo at night, try here.) The urban area of Tokyo and its surrounding areas are sprawling metropolis encompassing a staggering 34 million people. As a city itself, it lacks many of the architectural anachronisms of New York, but this is largely due to the fact that earthquakes knock many of them down every so often. In fact, because the islands are perpetually changing shape (earthquakes, volcanoes, waves), the Japanese could be said to rely more on social structure to preserve their cultural heritage than to rely on architectural cues as is the case in Europe (think: the Palace at Versailles).
 My adventures in Tokyo began the night I arrived. After meeting up with friend Chris Salzberg (currently working on a PhD at U. Tokyo, doing cool artificial life stuff), I experienced the tightly packed urban eating area in Shinjuku where salarymen eat a variety of Japanese cuisine in small shops that seat at most six or seven. The next morning, I rose at 4:30am to go to the Tokyo Fish Market, which my Let's Go guidebook recommended (although, I can't recommend the Japan guidebook). Just like Shinjuku train station, the Fish Market is the largest in the world. 27 tonnes of fish pass through the market every day (except Sunday), chilled by 200 tonnes of ice! The market itself starts up at around 3:00am, so by the time I arrived at 6:30am, things were in full swing. The daily auctions of freshly caught tuna had just finished, and rows upon rows of flash-freezed tuna carcasses lay on the auction house floors. From there, the fish were transferred to about a dozen densely packed rows of processing merchants who, with band-saws and 4-ft long knives, sliced and carved the tuna into progressively smaller chunks. Tuna isn't the only thing that passes through the market. There are so many things that do, I was at a loss to identify all but a few familiar ones: sea cucumbers, tuna, giant crabs, spiny lobsters (I think), squid, cuttlefish (maybe), and a host of other finned, shelled and tentacled things.
My adventures in Tokyo began the night I arrived. After meeting up with friend Chris Salzberg (currently working on a PhD at U. Tokyo, doing cool artificial life stuff), I experienced the tightly packed urban eating area in Shinjuku where salarymen eat a variety of Japanese cuisine in small shops that seat at most six or seven. The next morning, I rose at 4:30am to go to the Tokyo Fish Market, which my Let's Go guidebook recommended (although, I can't recommend the Japan guidebook). Just like Shinjuku train station, the Fish Market is the largest in the world. 27 tonnes of fish pass through the market every day (except Sunday), chilled by 200 tonnes of ice! The market itself starts up at around 3:00am, so by the time I arrived at 6:30am, things were in full swing. The daily auctions of freshly caught tuna had just finished, and rows upon rows of flash-freezed tuna carcasses lay on the auction house floors. From there, the fish were transferred to about a dozen densely packed rows of processing merchants who, with band-saws and 4-ft long knives, sliced and carved the tuna into progressively smaller chunks. Tuna isn't the only thing that passes through the market. There are so many things that do, I was at a loss to identify all but a few familiar ones: sea cucumbers, tuna, giant crabs, spiny lobsters (I think), squid, cuttlefish (maybe), and a host of other finned, shelled and tentacled things.
On the subway to the market, I met Sue and Ann, two South African sisters. Both were twice my age, but we had a great time strolling through the bustling market. Sue had been to the market once before, and shared the statistics I mentioned earlier. At the far side of the market, the processed fish were packaged and moved so as to be transported to the far reaches of the globe. From what I hear, there are sushi restaurants in New York City that have their fish flown in daily from Tokyo. I've seen one end of the chain now, so next time I'm in New York, I'll have to see the other. My companions and I finished our tour with a breakfast of fresh sushi; delicious!
 My next stop was the neighborhood of Akihabara, which is better known for its cheap electronics and anime stores, but I was there to see a little Confucian shrine, and the shrine to Kanda Myojin (Japanese legendary figure). As seems pretty common in Tokyo, nestled among the endless tall buildings, bustling streets and fashy modernity are islands of aged tranquility. Smack in the middle of Akihabara is a walled compound that houses the Confucian shrine, and across the street is the Kanda shrine. Both were imperfect santuarie, as if, despite the stillness within, the young, modern and energetic Tokyo a few dozen meters away refused to be silenced by the stable, ancient and peaceful Tokyo of yesterday.
My next stop was the neighborhood of Akihabara, which is better known for its cheap electronics and anime stores, but I was there to see a little Confucian shrine, and the shrine to Kanda Myojin (Japanese legendary figure). As seems pretty common in Tokyo, nestled among the endless tall buildings, bustling streets and fashy modernity are islands of aged tranquility. Smack in the middle of Akihabara is a walled compound that houses the Confucian shrine, and across the street is the Kanda shrine. Both were imperfect santuarie, as if, despite the stillness within, the young, modern and energetic Tokyo a few dozen meters away refused to be silenced by the stable, ancient and peaceful Tokyo of yesterday.
 Next, I walked from Akihabara to Ueno, another major transportation hub much like Shinjuku. Situated just behind the station is the sprawling Ueno Park, home, it would seem, to most of the major museums in Tokyo. I focused my time in the Tokyo National Museum complex, which houses six different buildings containing art and treasures from historic Japan, as well as the rest of Asia. Apparently, the mummys are the main draw there and I missed them. Instead, I wandered amongst thousand year old urns, scrolls and statues of buddha. Of all the pieces, I enjoyed the black and white Japanese screens, and the 'modern' Japanese art, from the 1800s, that appeared to be slightly post-Renaissance and reminded me a little of Andy Warhol's stuff. Oh, and, the samurai armor was neat.
Next, I walked from Akihabara to Ueno, another major transportation hub much like Shinjuku. Situated just behind the station is the sprawling Ueno Park, home, it would seem, to most of the major museums in Tokyo. I focused my time in the Tokyo National Museum complex, which houses six different buildings containing art and treasures from historic Japan, as well as the rest of Asia. Apparently, the mummys are the main draw there and I missed them. Instead, I wandered amongst thousand year old urns, scrolls and statues of buddha. Of all the pieces, I enjoyed the black and white Japanese screens, and the 'modern' Japanese art, from the 1800s, that appeared to be slightly post-Renaissance and reminded me a little of Andy Warhol's stuff. Oh, and, the samurai armor was neat.
 Finally, I walked from Ueno to Asakusa (getting lost only a couple of times on the way - the directions in Let's Go Japan are universally bad for Tokyo; fortunately, the Japanese are often extremely helpful to lost foreigners) to see the famous Senso-ji shrine. "Shrine" doesn't really do it much justice - "campus" seems a better word. The main shrine is about the size of a small office building, and it's flanked by a huge and beautiful five story pagoda building. The small hut-like structure on the approaching road billows smoke that the Japanese waft towards themselves to get luck. At all the shrines I visisted, the offering box is situated in front of the buddha and is fitted with wooden slats running short-ways across the top - coins tossed onto them make a pleasing thunk-thunk-chink as they bounce across them before finally settling into the interior. The offering box at Senso-hi was proportionate to the size of the shrine... that is to say, it was huge, and patrons tossed their coins from a proportional distance away. After snapping some pictures of this sprawling and very traditionally Japanese structure, I browsed the shopping street nearby. Tourist-trap central, although a lot of the goods are hand-crafted. I hear that it used to be more pleasant (read: less touristy), but I found it nice enough.
Finally, I walked from Ueno to Asakusa (getting lost only a couple of times on the way - the directions in Let's Go Japan are universally bad for Tokyo; fortunately, the Japanese are often extremely helpful to lost foreigners) to see the famous Senso-ji shrine. "Shrine" doesn't really do it much justice - "campus" seems a better word. The main shrine is about the size of a small office building, and it's flanked by a huge and beautiful five story pagoda building. The small hut-like structure on the approaching road billows smoke that the Japanese waft towards themselves to get luck. At all the shrines I visisted, the offering box is situated in front of the buddha and is fitted with wooden slats running short-ways across the top - coins tossed onto them make a pleasing thunk-thunk-chink as they bounce across them before finally settling into the interior. The offering box at Senso-hi was proportionate to the size of the shrine... that is to say, it was huge, and patrons tossed their coins from a proportional distance away. After snapping some pictures of this sprawling and very traditionally Japanese structure, I browsed the shopping street nearby. Tourist-trap central, although a lot of the goods are hand-crafted. I hear that it used to be more pleasant (read: less touristy), but I found it nice enough.
 On my second day, I ventured to Harajuku neighborhood to see the "fashion parade" of young girls wearing outlandish costumes (accompanied by Chris and Hana). At first, I had much respect for them since I thought they much have made these costumes themselves. Then, as we walked from Harajuku to Shibuya for lunch, I spotted a host of stores that sell these get-ups pre-made. The outlandishness suddenly became both less endearing and less interesting. But my faith in Japanese weirdness was restored when I came upon a group of four Japanese men outfitted in tight leather and copious amounts of hair grease, dancing to "Do The Twist" in the nearby park. As any Japanese tourist would do, I snapped a picture of the crazy locals.
On my second day, I ventured to Harajuku neighborhood to see the "fashion parade" of young girls wearing outlandish costumes (accompanied by Chris and Hana). At first, I had much respect for them since I thought they much have made these costumes themselves. Then, as we walked from Harajuku to Shibuya for lunch, I spotted a host of stores that sell these get-ups pre-made. The outlandishness suddenly became both less endearing and less interesting. But my faith in Japanese weirdness was restored when I came upon a group of four Japanese men outfitted in tight leather and copious amounts of hair grease, dancing to "Do The Twist" in the nearby park. As any Japanese tourist would do, I snapped a picture of the crazy locals.
That night, Chris, Hana and I had what's called "munja", a kind of traditional Japanese food. The restaurant was small and run by a local family, the menu was in kanji; Hana ordered. Soon we were brought three bowls of chopped stuff (possibly soaking in a liquid), which is then fried on the hot plate built into your table. For one kind of munja, once it's partially fried, you carefully construct a little pen on the hot plate and pour the liquid from the bowl into the middle. If you've built properly then none of the liquid seeps out. Trying my hand at this, my dam only sprung one leak, and the final result was extremely tasty.
Tokyo, like New York City, is too big to see in a few days. As I've come to expect with all of my travel, many interesting things will go unseen and unexperienced. My rationalization is that I simply have to return in the future to experience more. Tokyo is no different. During my last day, I focused more on business, visiting both the Ikegami and Kaneko laboratories at U. Tokyo. My intention was to investigate the possibility of doing a post-doc in Kaneko's lab, and this may materialize in the future. My trip to Japan left me so enamored with the country that I've placed it on the (very short) list of places to live in the future.
posted April 9, 2005 12:33 AM in Travel | permalink | Comments (0)
April 05, 2005
Flying west to get east; follow-up
I just got back from Japan, and I want to go back already. Truly a country where East meets West, and Traditional meets Modern, and Nature meets Mankind (think: volanoes, earthquakes and tidal waves), Japan is an amazing place. Over the next little while, I'll be blogging about some of my experiences and observations about the differences between Japanese and Americans.
posted April 5, 2005 10:11 PM in Self Referential | permalink | Comments (0)
March 23, 2005
Flying west to get east
 In a few hours, I leave on my first trip to the Asian continent (I don't count my trip to Turkey in 2002). Depending on Internet access, time and motivation, I may make updates from abroad, but don't count on it. I'll definitely write something when I return, and post lots of pictures. Tenatively, I'll say that I'll resume my sporadic posting on April 5th.
In a few hours, I leave on my first trip to the Asian continent (I don't count my trip to Turkey in 2002). Depending on Internet access, time and motivation, I may make updates from abroad, but don't count on it. I'll definitely write something when I return, and post lots of pictures. Tenatively, I'll say that I'll resume my sporadic posting on April 5th.
My itinerary begins with flying into Tokyo, where I'll spend three or four days. In addition to seeing the sights and experiencing the megopolis, I'll be visiting friend Chris Salzberg and his research lab. It's always nice to mix a little business scouting in with all the pleasure. Who knows, maybe I'll apply for post-docs in Tokyo in a few years. After Tokyo, it's off to historic Kyoto where I'll fend for myself for several days, before finally heading to the southern island of Kyushu to visit friend Jenn Louie in the city of Miyazaki.
posted March 23, 2005 09:49 PM in Self Referential | permalink | Comments (0)
March 21, 2005
die Welt auf einer Zeichenkette
 One of the big three German language daily newspapers die Welt ran a story about our work on the power law in global terrorism (warning: in German; English translation) on its front page (above the fold) on Saturday, March 19. Google's translation of the article is less than pleasant, ah well. Should have paid more attention in my German language class in college.
One of the big three German language daily newspapers die Welt ran a story about our work on the power law in global terrorism (warning: in German; English translation) on its front page (above the fold) on Saturday, March 19. Google's translation of the article is less than pleasant, ah well. Should have paid more attention in my German language class in college.
(The image is © die Welt 2005)
posted March 21, 2005 11:47 AM in Self Referential | permalink | Comments (0)
March 01, 2005
Snowboarding
 This past weekend, I went snowboarding with friends at Wolf Creek. The last time I went boarding was about one year ago, also at Wolf Creek, but with a slightly different set of people. I still don't quite know if I'm going to board very often (so far, and this looks like it may continue for the foreseeable future, I'll be boarding for just one weekend per season), so I'm just renting stuff. Plus, I seem to have a propensity for equipment-heavy sports (e.g., rock climbing, scuba diving and snowboarding), which makes it very expensive to get gear for all of them.
This past weekend, I went snowboarding with friends at Wolf Creek. The last time I went boarding was about one year ago, also at Wolf Creek, but with a slightly different set of people. I still don't quite know if I'm going to board very often (so far, and this looks like it may continue for the foreseeable future, I'll be boarding for just one weekend per season), so I'm just renting stuff. Plus, I seem to have a propensity for equipment-heavy sports (e.g., rock climbing, scuba diving and snowboarding), which makes it very expensive to get gear for all of them.
Apparently, snowboarding is a lot like skateboarding. But when I was young and all of my friends were getting into it, I was never any good. I could get up on the skateboard for a little while, but as soon as I had to turn, or shift my weight, I would get a mouth full of gravel. Snowboarding is... a bit easier, and instead of gravel, you get a mouth full of snow. Angie and I are at roughly the same skill level now, and we found a great run under the Treasure Lift with a little bit of through-the-trees, and a lot of through-the-powder. I still don't have a lot of control over the board at high speeds (which makes wiping out painful... after hitting my head hard four or five times, I finally decided to make controlling my speed a priority!), but the powder makes crashing so much more pleasant. Next time, I think I might try some stuff on the Alberta face, which is mostly black runs.
posted March 1, 2005 04:10 AM in Self Referential | permalink | Comments (0)
January 31, 2005
On being interdisciplinary
 I've been on the East Coast for two weeks for reasons of both work and play. I started at the MIT Media Lab working with Nathan Eagle on some really amazing network analysis stuff. It was cold, there was some peripheral unpleasantness not connected with him (he was actually good about it as it was happening), but it was great to be in a totally new environment thinking about totally new things. Plus, I got to hang out with friends from the Santa Fe Institute summer school I went to a couple of years ago. Then I went to Holyoke where I got to visit an old old friend that I haven't seen in ages. Jessica drove me down to Yale, where I visisted my friend Robin Herlands which was wonderful and stimulating and fun, despite having 18 inches of snow dumped on us that weekend. I met her friends, played "Cups" for the first time (I'm a natural - who knew?), and bonded with her hyperactive kitten Charlie. Then, I went to New York City to see one of my closest guy friends Trevor Barran. Despite his being completely overworked, that week was fabulous at least for my being able to cavort in a city that I have fallen completely in love with over the the culture, the closeness, the speed and the density. Nights of drinking and philosophizing and meeting people, followed by days of work and wandering and wondering.
I've been on the East Coast for two weeks for reasons of both work and play. I started at the MIT Media Lab working with Nathan Eagle on some really amazing network analysis stuff. It was cold, there was some peripheral unpleasantness not connected with him (he was actually good about it as it was happening), but it was great to be in a totally new environment thinking about totally new things. Plus, I got to hang out with friends from the Santa Fe Institute summer school I went to a couple of years ago. Then I went to Holyoke where I got to visit an old old friend that I haven't seen in ages. Jessica drove me down to Yale, where I visisted my friend Robin Herlands which was wonderful and stimulating and fun, despite having 18 inches of snow dumped on us that weekend. I met her friends, played "Cups" for the first time (I'm a natural - who knew?), and bonded with her hyperactive kitten Charlie. Then, I went to New York City to see one of my closest guy friends Trevor Barran. Despite his being completely overworked, that week was fabulous at least for my being able to cavort in a city that I have fallen completely in love with over the the culture, the closeness, the speed and the density. Nights of drinking and philosophizing and meeting people, followed by days of work and wandering and wondering.
One of the things I love most about my line of work is that it's largely quite accessible to smart people who aren't in my field. It's even accessible to people who aren't in academia at all. Sharing these things and getting people excited about the work is what makes me believe that what I'm doing is perhaps meaningful or worthwhile. And given the unrelenting pressure to produce new results at a constant (or accelerating) rate, this kind of support is like oxygen. In meeting so many new people during the past few weeks, I often got asked to describe my research. This is hard: I don't have a niche; I don't have a well-defined field. There is no obscure property of a complicated system that will bear my name, and there is no unifying framework that my work nicely fits inside of.
So, I've used the term "research cowboy" to describe what I do, since my work bears rough similarities to riding into a town, solving some problems that no one else has solved yet, and then riding out of town before I get too comfortable. I should make the French surrealist painter Francis Picabia my patron, for having once uttered the words "One must be a nomad, traveling through ideas as one travels through countries and cities." This is exactly what I find so stimulating about academia, but if it can't support my habit for the long term, then ultimately, I'm going to want out. The only distinctions I see between fields like physics, chemistry, biology and geopolitics are those arising from our inability to sufficiently understand their similarities and their structure. The universe makes no distinction between these things, so why do we?
My advisor once said to me that being interdisciplinary is both easy and hard. On the one hand, there is often a lot more "low hanging fruit" (oh, how academics overuse that phrase) in interdisciplinary fields, but on the other, endemic ideological gravitation requires that is one is twice as smart, twice as rigorous and twice as good at explaining the relevance of one's results in order to be taken seriously by the fields one is jostling. There is no Nature or Physical Review Letters for interdisciplinary work, and there are no Departments of Interdisciplinary Research.
And so, I am worried about several things. I am worried that I don't have the endurance to keep up with the grueling work schedule that academic research entails. I am worried that I won't continue to have interesting things to say about the world in my ill-defined fields. And I am worried that because I am neither a physicist nor a computer scientist that I won't be able to find a job in either, or that whatever job I do end up finding won't provide me the flexibility that I need. If I can't be interdisciplinary, I can't keep working. Does anyone know of any openings for a Research Cowboy?
posted January 31, 2005 10:32 AM in Self Referential | permalink | Comments (2)
January 01, 2005
Publications and Publicity
- On the Frequency of Severe Terrorist Attacks.
A. Clauset, M. Young and K. S. Gleditsch.
Journal of Conflict Resolution 51(1): 58 - 88 (2007). - Structural Inference of Hierarchies in Networks.
A. Clauset, C. Moore and M. E. J. Newman.
in Proceedings of 23rd International Conference on Machine Learning (ICML), Workshop on Social Network Analysis.
To appear in Lecture Notes in Computer Science, Springer (2006). - Scale Invariance in Road Networks.
V. Kalapala, V. Swanwalani, A. Clauset and C. Moore.
Physical Review E 73, 026130 (2006). - Molecular modeling of mono- and bis-quaternary ammonium salts as ligands at the a4b2 nicotinic acetylcholine receptor subtype using nonlinear techniques.
J. T. Ayers, A. Clauset, J.D. Schmitt, L. P. Dwoskin and P. A. Crooks.
American Association of Pharmaceutical Scientists Journal 7(3): E678-85 (2005). - Supervised Self-Organizing Maps in QSAR I: Robust behavior with underdetermined datasets.
Y.D. Xiao, A. Clauset, R. Harris, E. Bayram, P. Santago II, and J.D. Schmitt.
J. Chemical Information and Modeling 46(6): 1749-1759 (2005). - Finding local community structure in networks.
A. Clauset.
Physical Review E 72, 026132 (2005). - On the Bias of Traceroute Sampling (or: Why almost every network looks like it has a power law).
D. Achlioptas, A. Clauset, D. Kempe and C. Moore.
in Proceedings of 37th ACM Symposium on Theory of Computing (STOC) 2005 (Baltimore, May 21-24). - Accuracy and Scaling Phenomena in Internet Mapping.
A. Clauset and C. Moore.
Physical Review Letters 94, 018701 (2005). - Finding community structure in very large networks.
A. Clauset, M.E.J. Newman and C. Moore.
Physical Review E 70, 066111 (2004).
Download the code - Genetic Algorithms and Self-Organizing Maps: A Powerful Combination for Modeling Complex QSAR and QSPR Problems.
E. Bayram, P. Santago II, R. Harris, Y. Xiao, A. Clauset and J.D. Schmitt.
J. Computer-Aided Molecular Design 18 (7-9): 483-493 (2004). - How Do Networks Become Navigable?
A. Clauset and C. Moore.
prepint (2003). - Chaos You Can Play In.
A. Clauset, N. Grigg, M.T. Lim, and E. Miller.
Proceedings of the SFI CSSS (Santa Fe, August 2003)
Publicity

|
Mapping the Internet SIAM News (June 2005) |

|
Scale Invariance in Global Terrorism PhysicsWeb (February 2005)Nature News (February 2005) Die Welt (March 2005, in German) Nature News (July 2005) The Economist (July 2005) The Guardian (August 2005) |
|
How Do Networks Become Navigable? This paper appeared as part of the course packet for Jon Kleinberg's "Algorithms for Information Networks" course during Spring 2005 at Carnagie Mellon University. |
posted January 1, 2005 02:50 AM in Self Referential | permalink | Comments (0)
About me
This blog is a dumping-zone for rambling thoughts, half-baked ideas, musings and other expositions on topics that I find interesting. So far, it's been primarily a semi-professional effort, as I've focused on things related to research, academia, society, the world, etc. etc. etc. But, I've also thrown in some travel information and other personal information that seems like it might be interesting to readers.
As for me, I am currently in the final stretch of my PhD in Computer Science at the University of New Mexico. I've been here since the Fall of 2002, but in January 2007, I'll be joining the Santa Fe Institute as a post-doctoral researcher. My research focuses primarily on the structure and function of complex networks, through statistical modeling and data analysis. Examples here include road networks, the World Wide Web and the Internet, cellular networks of various kinds, power-transmission networks, recommender and citation networks, and social networks of various other kinds.
My work on mapping the structure of the Internet has received some attention in the press, as has my work on the statistics of terrorism. Lately, I've been focusing on characterizing and modeling the global topological properties of networks, and in particular their heterogeneous organization (e.g., communities and hierarchy). I'm also interested in macro-evolution, ecology and scaling laws, but this is a fairly recent fascination of mine.
Finally, my Erdös Number is 3 by the following chain: Paul Erdös, Mike Molloy, Cristopher Moore, me.
-- Aaron Clauset --
posted January 1, 2005 02:30 AM in Self Referential | permalink | Comments (0)